Google Search Console 인덱싱 자동화, 인덱싱 오류가 발생할 때
Google Search Console 인덱싱 자동화
Indexing 자동화
배경
Google Search Console에 블로그를 등록하면, 구글이 자동으로 사이트맵을 읽어오고 사이트맵에 있는 URL을 통해 인덱싱을 진행한다. 하지만, 생각보다 시간이 오래 소요된다. (필자의 경우 2주 이상)
[문제의 사진]
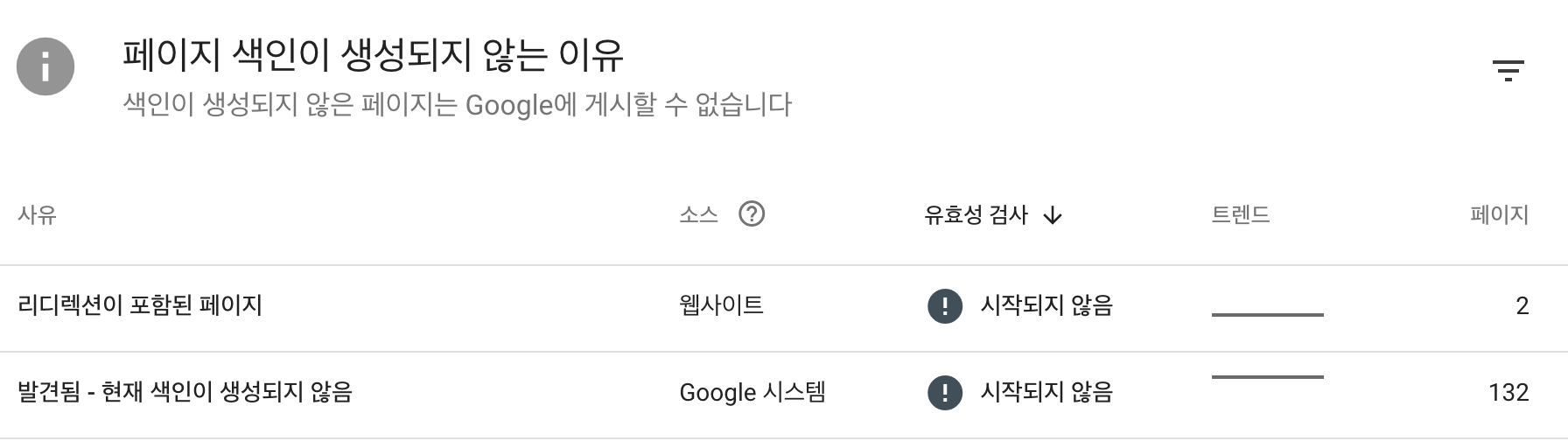
2주 정도 기다렸는데 반영이 안되어있길래, 오류가 있는지 검사하고 수동으로 신청을 해봤다. 수동으로는 요청 후 1~2일후에 인덱싱이 되었다. 하지만 페이지의 개수가 150개 이상..그리고 페이지 하나당 처리를 기다리는데 시간이 오래걸린다. 그래서 API를 통해 사이트맵에 있는 URL 인덱싱을 요청하기로 한다.
사전 준비
Indexing 요청을 진행하려면 Google API를 사용해야한다. 사용할 때, 여러 인증 절차가 있어 복잡하다.
우선 Google Cloud에서 Services Account를 만들고 API를 활성화하고, Google SearchConsole에서 앞서 만든 Service Account 계정 등록이 필요하다.
[Google Cloud 설정]
- GoogleCloud에 접속하여, 새로운 프로젝트를 생성한다.
- 왼쪽 메뉴머튼을 통해 API 및 서비스에 접속한다.
- OAuth 동의 화면을 선택하여 진행한다.
- 기본정보
- User Type 외부
- 사용자 지원 이메일: 본인 이메일
- 나머진 패스
- 범위는 별도로 입력하지 않아도 된다.
- 테스트 사용자는 자신의 이메일을 입력한다.
- 기본정보
- OAuth 동의 화면을 선택하여 진행한다.
- API 및 서비스 > 사용자 인증정보에 접속하여 서비스 계정을 생성한다.
- 서비스 계정을 생성한다.
- Key를 생성한 뒤, JSON 파일을 다운받는다.
- (1)서비스 계정의 이메일은 저장해둔다. 아래의 Google Search Console에서 사용한다.
- API 및 서비스 > API 라이브러리 > Web Search Indexing API을 검색하여 사용을 시작한다.
- Indexing과 관련된 API로 우리가 사용할 API이다.
[Google Search Console 설정]
위에서 생성한 Services Account 계정을 Search Console에도 등록한다.
- Google Search Console에 접속하여 자신의 도메인을 선택한다.
- 왼쪽 메뉴에서 설정 > 사용자 및 권한을 선택한다.
- 사용자 추가버튼을 누르고, 위에서 만든 Servcies Account를 소유자 권한으로 추가한다.
- (1)에서 저장해둔 이메일을 입력한다.
__@__.iam.gserviceaccount.com와 같은 형태의 이메일을 추가한다.
- (1)에서 저장해둔 이메일을 입력한다.
이러면 기본적인 세팅은 끝났다. 이제 앞에서 받은 JSON 파일을 코드를 실행시킬 공간에 옮긴다.
프로젝트
Indexing API와 관련된 공식 문서는 링크를 통해 확인할 수 있고, 여기서 임의로 테스트할 수 있다.
[변경해야 할 부분]
sitemap_url: 자신의 웹사이트의 사이트맵 주소를 입력한다.JSON_KEY_FILE: 자신의 JSON 파일명을 입력한다.
[코드 구조]
- 블로그 사이트에서 sitemap을 가져온다. 사이트맵에서 URL을 모두읽어와 리스트로 저장한다.
- 각 URL을 조회하여 인덱싱요청을 과거에 한적이 있는지 파악한다. 없다면, 404 에러를 발생시킨다.
- 404에러 URL은 새로운 페이지이므로 인덱싱 등록을 요청한다.
[의존성]
해당 코드는 아래의 버전으로 동작하기에 가상환경을 만드는 것이 좋다.
1
python -m venv venv
코드를 입력하여 가상환경을 생성한다. 그러면 프로젝트에 venv 폴더가 생성되는 것을 확인할 수 있다.
1
source venv/bin/activate
이제 아래의 의존성을 다운받는다.
1
2
3
oauth2client==4.1.3
httplib2==0.22.0
requests==2.24.0
[소스 코드]
프로젝트는 GitHub를 통해서 확인할 수 있습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
import json
import os
import requests
import httplib2
import xml.etree.ElementTree as ET
from oauth2client.service_account import ServiceAccountCredentials
def fetch_and_parse_xml(url):
# XML 콘텐츠 가져오기
response = requests.get(url)
response.raise_for_status()
# XML 파싱
root = ET.fromstring(response.content)
# <loc> 태그 내 URL 추출
namespace = {'ns': 'http://www.sitemaps.org/schemas/sitemap/0.9'}
urls = [element.text for element in root.findall('ns:url/ns:loc', namespace)]
return urls
def http_request(http, endpoint, method, json_content):
response, content = http.request(
endpoint,
method=method,
body=json_content,
headers={'Content-Type': 'application/json'}
)
return response, content
def handler():
sitemap_url = '~~/sitemap.xml'
urls = fetch_and_parse_xml(sitemap_url)
JSON_KEY_FILE = "~.json"
scopes = ["https://www.googleapis.com/auth/indexing"]
credentials = ServiceAccountCredentials.from_json_keyfile_name(JSON_KEY_FILE, scopes=scopes)
http = credentials.authorize(httplib2.Http())
for url in urls:
endpoint_meta = "https://indexing.googleapis.com/v3/urlNotifications/metadata?url=" + url
response, content = http_request(http, endpoint_meta, "GET", "")
if response.status == 404:
print(f"URL not found: {url}")
content = {
"url": url,
"type": "URL_UPDATED"
}
json_content = json.dumps(content)
response, content = http_request(http, "https://indexing.googleapis.com/v3/urlNotifications:publish", "POST", json_content)
print(f"Indexing {url}: {response.status}")
# return {
# 'statusCode': 200,
# 'body': json.dumps('URL Indexing Complete')
# }
handler()
정리
귀찮은 작업을 API를 통해 빠르게 코드를 제작할 수 있었다. 코드는 일단 AWS Lambda 형식으로 만들었는데, 아직은 클라우드로 옮길 이유를 못찾겠어서 로컬에서 돌리고 있다. 아직 인덱싱 결과는 안나왔는데, 결과가 나오면 업데이트 예정이다. 수동으로 했을 때 1~3일 정도 소요됐다. 현재(2024/01/24) 코드를 실행했으니, 3일 정도 뒤에 업데이트가 되면 결과를 정리해서 업데이트할 예정이다.
*업데이트 결과(2024/01/25)
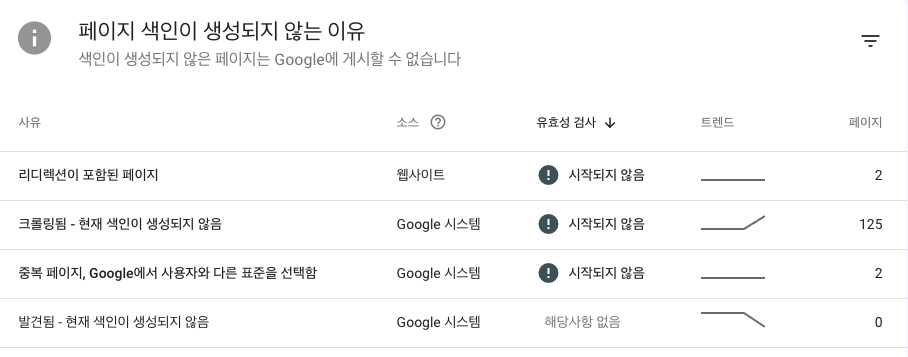
업데이트 결과 다음과 같이, 크롤링됨 - 현재 색인이 생성되지 않음으로 바뀌었다. 하지만, 실제 구글에 포스팅 제목으로 검색해보면 잘나오는 것을 확인할 수 있다.
추가로 API 요청 할당량이 존재한다. publish는 하루당 200개, getMetadata는 분당 180개, 모든 API 총합 할당량은 분당 600개이다. 페이지 수가 200개가 넘어가면 메타데이터를 조회하여 URL을 선택하는 과정에서 할당량을 넘어서게 된다. 별도로 publish 요청을 한 URL을 저장하는 방식으로 getMetadata API 양을 줄여야 할 것 같다.