etcd 정리
etcd와 raft algorithm이란?
etcd
key-value 형태의 데이터를 저장하는 스토리지로, 쿠버네티스에서 현재 클러스터의 상태와 원하는 상태(desired state)를 저장한다. 컨트롤러는 etcd를 통해 클러스터를 원하는 상태가 되도록, 백그라운드에서 작업한다. 만약 etcd가 없다면, 쿠버네티스의 모든 리소스는 제대로 동작하지 못하므로 HA가 보장되어야 한다. etcd는 상태 복제 머신으로 가용성을 유지하며, 내부적으로는 Raft Algorithm을 통해 일관성을 보장한다.
상태 복제 머신과 Raft 알고리즘은 어떻게 가용성을 확보할 수 있는 것인지, 아래에서 자세히 살펴본다.
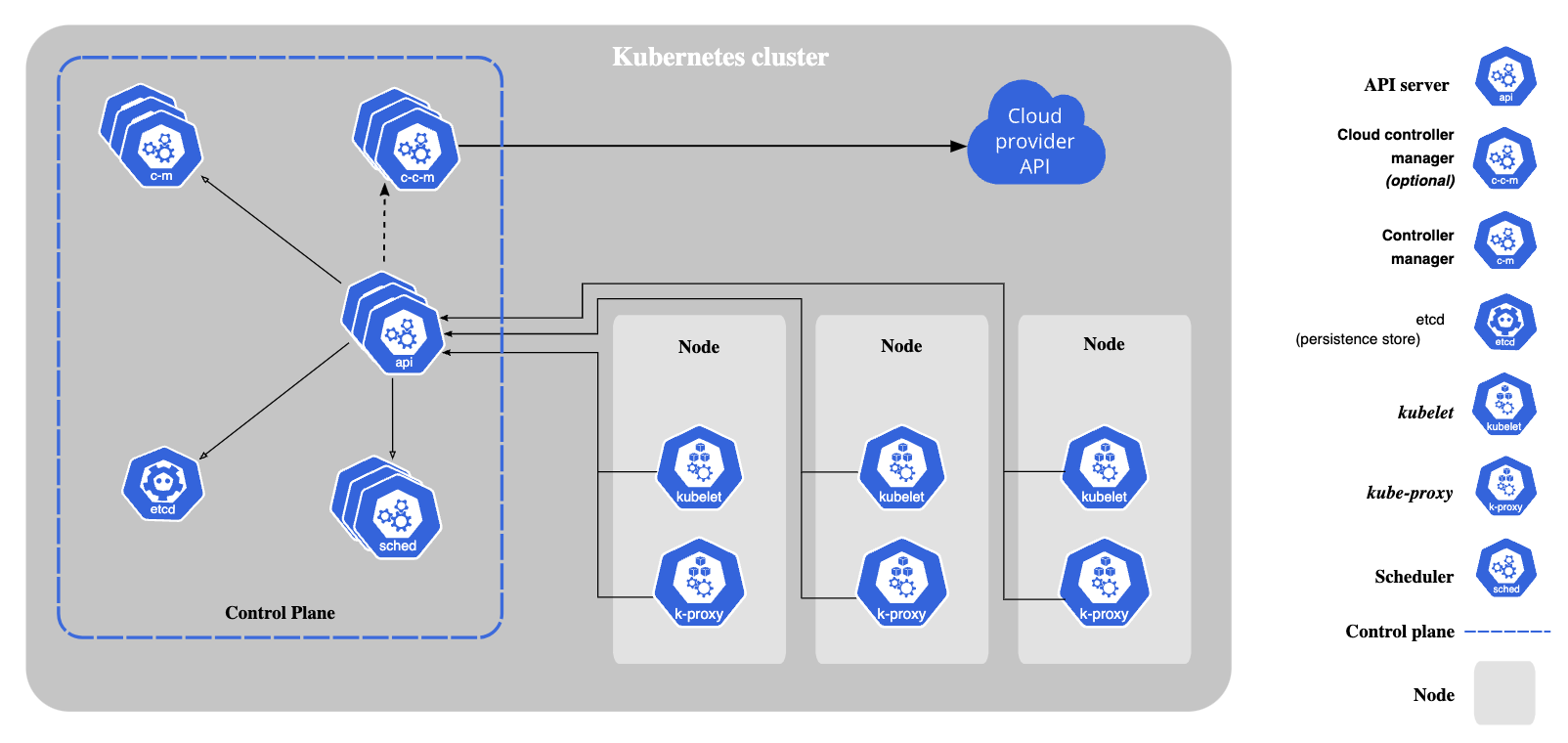
[출처: https://kubernetes.io/docs/concepts/overview/components/ ]
RSM
etcd는 RSM(Replicated state machine)으로 같은 데이터를 여러 개의 서버에 복제하는 머신이다.
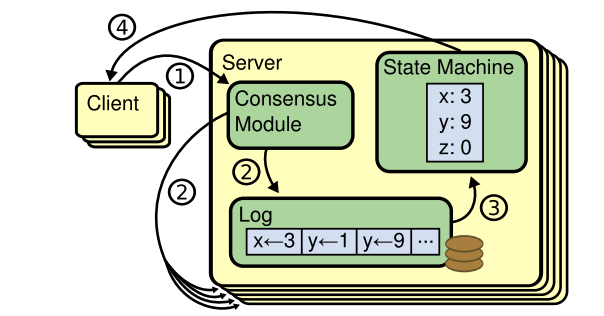
출처: https://raft.github.io/raft.pdf
내가 어떤 데이터를 업데이트하면, 로그에 관련된 내용이 추가된다. 위의 그림에서는 [x = 3, y = 1, y = 9] 명령이 순서대로 있는 것이다. 로그를 통해 상태 머신에서 상태의 값을 변경한다. (3)번 과정이 끝나면 내가 상태머신에서 y를 읽으면 9를 리턴받게 된다. 그리고 모든 상태머신에 로그를 전달했으면, 해당 내용을 커밋한다.(디스크의 저장한다.)
Raft Algorithm
뗏목 알고리즘은 분산 시스템에서 모든 노드가 동일한 상태를 유지하도록 하며, 일부 노드에 결합이 생겨도 전체 시스템의 문제가 없도록하는 방법이다. 여기서 정족수라는 개념을 사용하는데, 합의가 필요한 의사결정을 정족수를 기반으로 진행한다. 예를 들어, “x의 값을 3으로 업데이트”와 같은 행동을 정족수 이상의 노드가 합의해야 진행한다. 여기서 주요 개념에 대해 아래에서 알아본다.
정족수
어떤 의사 결정을 할 때는 정족수이상의 노드가 필요하다. 정족수는 과반수를 의미하며 전체 인원이 4명이면 3명, 3명이면 2명이 정족수이다.
노드의 상태
각 노드는 리더(Leader), 팔로워(Fllower), 후보자(Candidate) 중 하나의 역할을 수행한다. 클라이언트로 로그(상태 업데이트)를 받고, 이를 팔로워에게 전파하는 것은 리더만 할 수 있으며 리더는 단 한명만 존재한다.
리더 선출 방식
그렇다면 리더를 선출하는 방식은 무엇일까?
리더는 주기적으로 나머지 노드들에게 HeartBeat를 전송하여 자신이 건재함을 알려야한다. 팔로워는 한동안 리더에게 Heartbeat를 받지 못한다면 자신이 Term(임기)를 1 증가시키고 후보자로 상태를 변경한다.
후보자는 다른 노드들에게 자신의 리더 승진 투표를 요청한다. 투표 요청에는 자신의 임기(Term)와 Log에 대한 정보가 담겨있다. 투표자들은 임기와 Log를 확인하고, 최신의 상태인지 확인한 다음 ‘승낙 혹은 거절’한다. 투표 결과 정족수 이상의 응답을 받으면, 리더로 상태를 변경하며 자신의 임기를 공유한다. 나머지 노드는 임기를 동기화한다.
만약 동시에 후보자가 2명이고, 받은 응답의 수 또한 같다면? 재투표를 진행한다. 하지만, 이를 방지하기 위해 타이머를 랜덤하게 설정한다. 그렇기에 동시에 후보자가 2명일 확률은 현저히 적다.
로그 복제
클라이언트는 리더에게 명령을 전달한다. 예를 들어, X=1 명령을 전달했다고 가정하면 리더는 팔로워들에게 로그를 전달한다. 각 팔로워들은 로그를 잘 받았다고 응답을 보내며, 리더는 응답의 수가 정족수를 넘어가면 커밋을 진행한다.
ex) 리더는 팔로우들의 로그 인덱스를 가지고 있는데, 아래의 그림과 같은 경우라면 (위에서부터) [5, 8, 2, 7] 을 가진다. 리더는 현재의 상태에 맞게 부족한 팔로워들에게 로그를 반복적으로 전송한다. 지속적인 전송을 통해 클러스터 전체의 최신화 및 동기화가 유지된다.
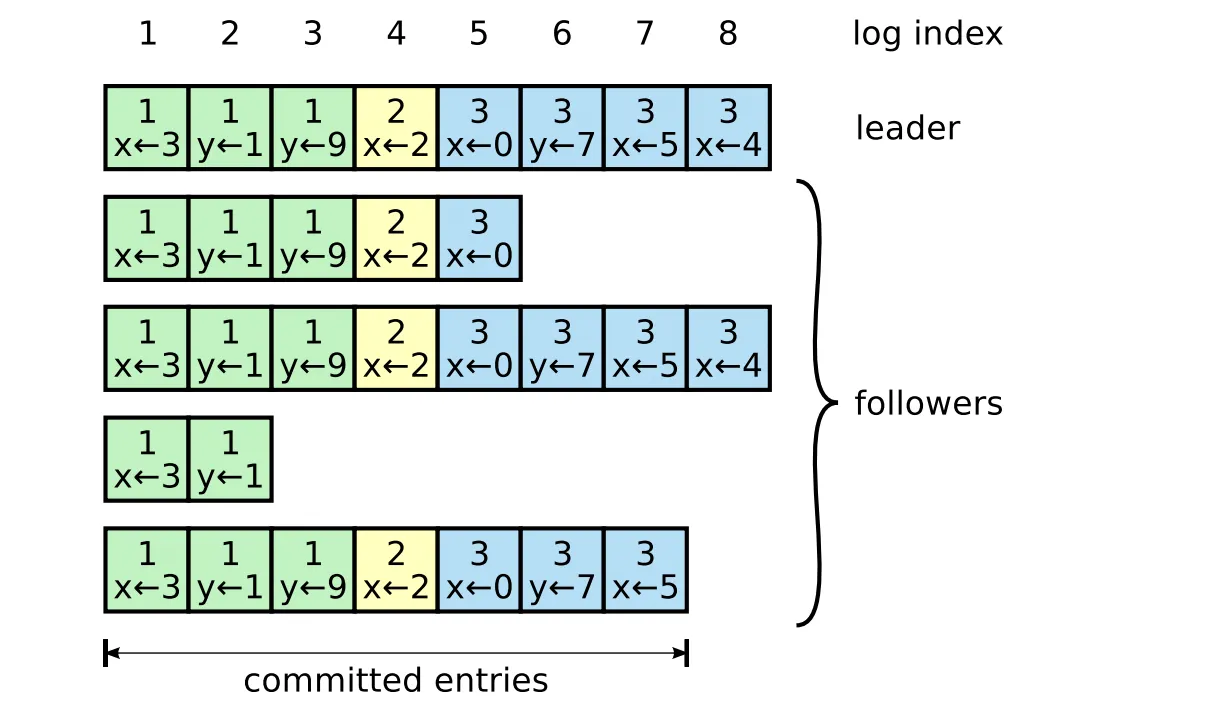
[ 출처: https://raft.github.io/raft.pdf ]
etcd 서버 추가
만약, A 서버를 추가하라는 명령을 받으면 리더는 다른 팔로워들에게 Config 수정에 대한 로그를 전송한다. 새로운 Config를 통해 모든 노드들은 새로운 노드가 추가된 것을 알 수 있다. 정족수 또한 업데이트 된다.
새로운 서버에게 가장 최신의 스냅샷을 보내준다. 새로운 서버는 최신의 스냅샷을 받아 디스크에 저장하고, 리더로 부터 추가적인 로그를 받아 복제한다.
만약, 새로운 노드가 스냅샷을 복원하는 중 새로운 노드가 추가된다면, 정족수는 늘어났지만 Ready 상태가 아닌 노드가 2개나 발생한다. 이럴 경우 commit이 거절될 수 있다. 이를 방지하고자 etcd 3.4.0에서는 Learner 상태를 추가했다. Learner는 정족수에 계산되지 않는다.
정리
etcd는 쿠버네티스에서 아주 중요한 요소 중에 하나이다. etcd의 가용성을 확보하는 것은 중요한데, etcd는 내부적으로 RSM 구조이며 정족수 기반으로 의사결정을 진행하는 Raft 알고리즘을 채택했다. 덕분에 네트워크가 분리되거나, 노드에 장애가 발생해도 과반수 이하라면 정상적으로 작동한다.
커피고래님의 [번역] 쿠버네티스 2,500대 노드 운영하기 포스팅을 통해 많은 노드를 운영할 때, etcd와 관련된 각종 문제들도 엿볼 수 있다. etcd의 가용성에 대한 고민을 하는데, 도움이 될 것 같다.
참고자료
https://raft.github.io/raft.pdf
https://medium.com/rate-labs/raft-consensus-이해-가능한-합의-알고리즘을-위한-여정-f7ecb9f450ab