AWS EKS Network 살펴보기
KANS 9주차 마지막 스터디 주제인 EKS Network 살펴보기
💡 KANS 스터디
CloudNet에서 주관하는 KANS(Kubernetes Advanced Networking Study)으로 쿠버네티스 네트워킹 스터디입니다. 아래의 글은 스터디의 내용을 기반으로 작성했습니다.스터디에 관심이 있으신 분은 CloudNet Blog를 참고해주세요.
실습 환경 설정
VPC 1개(퍼블릭 서브넷 3개, 프라이빗 서브넷 3개), EKS 클러스터(Control Plane), 관리형 노드 그룹(EC2 3대), Add-on(kube-proxy, coredns, aws vpc cni)으로 구성되어있다.
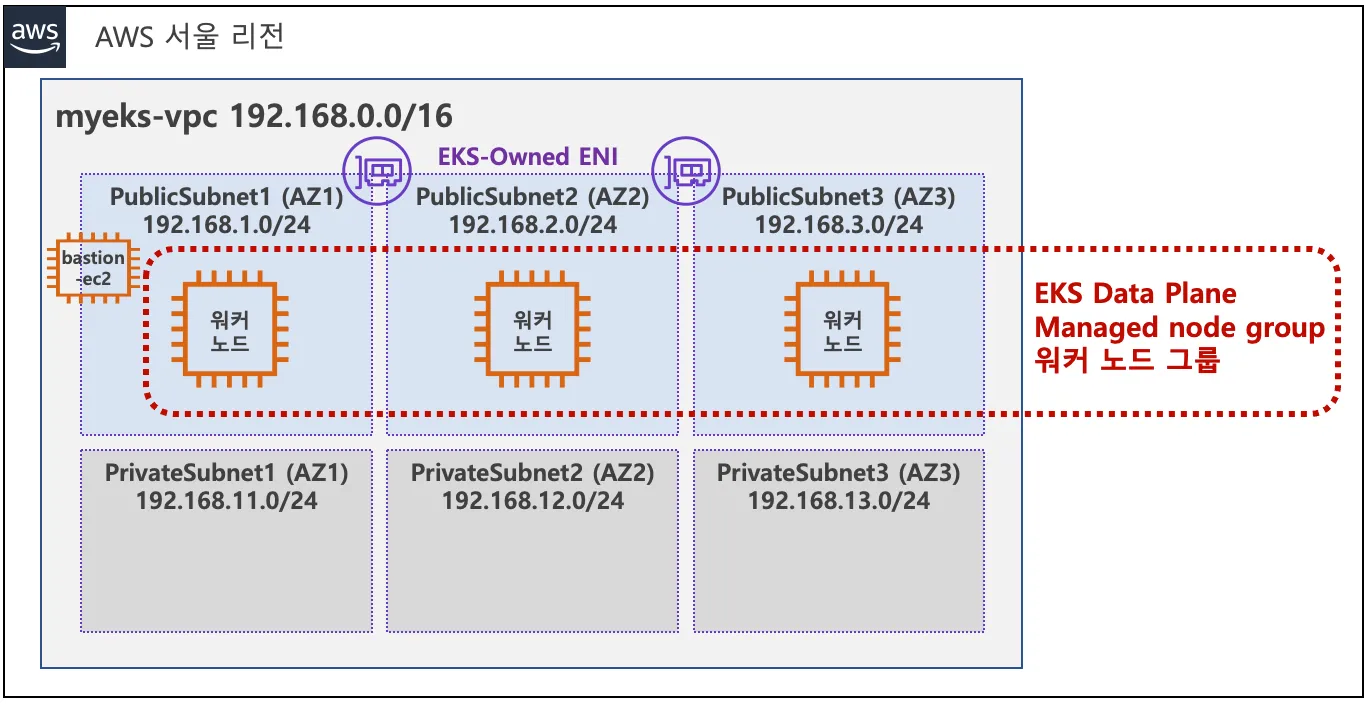
실습 환경 구성
CloudNet에서 준비해주신 eks-oneclick.yaml을 받고, 이를 통해 배포한다.
1
2
3
4
aws cloudformation deploy --template-file eks-oneclick.yaml --stack-name myeks --parameter-overrides KeyName=m1-pro SgIngressSshCidr=$(curl -s [ipinfo.io/ip](http://ipinfo.io/ip))/32 MyIamUserAccessKeyID=A.. MyIamUserSecretAccessKey='7..' ClusterBaseName=myeks --region ap-northeast-2
Waiting for changeset to be created..
Waiting for stack create/update to complete
Successfully created/updated stack - myeks
이상 실습에 필요한 세팅 진행
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
kubectl ns default
# 노드 정보 입력
aws ec2 describe-instances --query "Reservations[*].Instances[*].{PublicIPAdd:PublicIpAddress,PrivateIPAdd:PrivateIpAddress,InstanceName:Tags[?Key=='Name']|[0].Value,Status:State.Name}" --filters Name=instance-state-name,Values=running --output table
**N1=$(**kubectl get node --label-columns=topology.kubernetes.io/zone --selector=topology.kubernetes.io/zone=ap-northeast-2a -o jsonpath={.items[0].status.addresses[0].address})
**N2=$**(kubectl get node --label-columns=topology.kubernetes.io/zone --selector=topology.kubernetes.io/zone=ap-northeast-2b -o jsonpath={.items[0].status.addresses[0].address})
**N3=$(**kubectl get node --label-columns=topology.kubernetes.io/zone --selector=topology.kubernetes.io/zone=ap-northeast-2c -o jsonpath={.items[0].status.addresses[0].address})
echo "export N1=$N1" >> /etc/profile
echo "export N2=$N2" >> /etc/profile
echo "export N3=$N3" >> /etc/profile
echo $N1, $N2, $N3
# 보안 그룹 세팅
aws ec2 describe-security-groups --filters Name=group-name,Values=***ng1*** --query "SecurityGroups[*].[GroupId]" --output text
NGSGID=$(aws ec2 describe-security-groups --filters Name=group-name,Values=***ng1*** --query "SecurityGroups[*].[GroupId]" --output text)
echo $NGSGID
echo "export NGSGID=$NGSGID" >> /etc/profile
# SSH 연결진행
for node in $N1 $N2 $N3; do ssh -o StrictHostKeyChecking=no ec2-user@$node hostname; done
vpc-cni
vpc-cni에 대해 자세히 알기전에 먼저 AWS의 네트워크 인터페이스인 ENI에 대해 알아본다.
ENI(Elastic Network Interface)는 VPC에서 가상 NIC에 대한 인터페이스이다. AWS 콘솔에서 보는 NIC 자체가 모두 ENI이다. ENI에는 보조 인터페이스(secondary IP)를 붙일 수 있는데, 이는 Docs에서 확인가능하다.
예를 들어, t3.medium 의 경우 ENI 마다 5개의 Secondary IP를 가질 수 있다
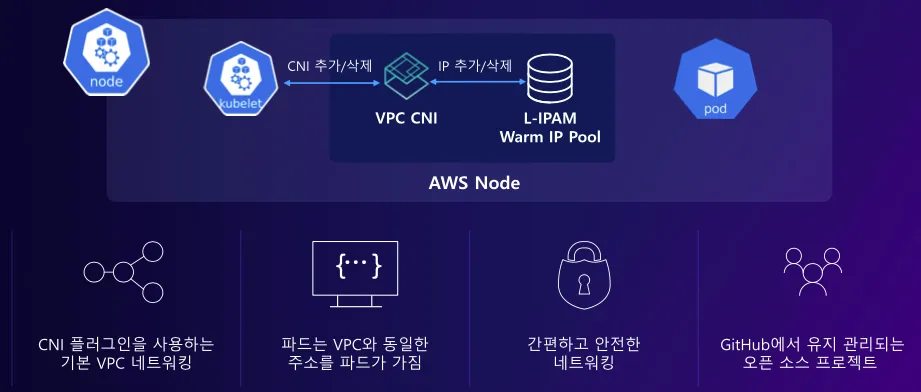
파드 IP CIDR
파드의 네트워크 대역과 노드의 네트워크 대역이 같다. 이를 통해 네트워크 최적화가 가능하다.
- 장점: 파드 통신에 대한 네트워크 비용을 절약할 수 있다.(오버레이, 불필요한 hop 제거)
- 단점: 파드와 노드의 IP 대역이 같아, 파드 개수의 제한이 있다.
특정 서비스 파드는 리소스를 많이 가져가므로, 어떤 서비스에선 파드의 개수가 적을 수 있다. 하지만 반대로 스팟성으로 한번에 많은 파드가 필요한 서비스도 있을 것이다. 그렇기에 VPC-CNI를 사용한다면 클러스터를 생성할 때부터 노드의 Spec과 개수를 심도있게 고민하여 선택하는 게 좋을 것 같다.
ENI 할당
하나의 ENI의 Secondary IP가 모두 소모되면 새로운 ENI가 추가된다. 각 EC2 Spec 별로 최대 ENI의 개수가 지정되어있다. Secondary IP 또한 Spec 별로 설정된다.
최대 파드 개수
파드에 할당할 수 있는 IP는 정해진다. the number of ENIs for the instance type × (the number of IPs per ENI - 1)) + 2 그렇다고 방법이 없는 것은 아니다. IPv4 Prefix Delegation으로 추가적인 IP 대역을 확보할 수 있다.
접두사 할당모드를 사용하면 인스턴스 타입 별 ENI의 개수 제한은 같지만, 하나의 ENI당 사용할 수 있는 Secondary IP 풀이 늘어난다. 즉, ENI에 Secondary IPv4 주소를 할당하는 대신에 /28(16개) IPv4 주소 접두사를 할당하면 노드 당 실행할 수 있는 최대 파드 수를 늘릴 수 있다.
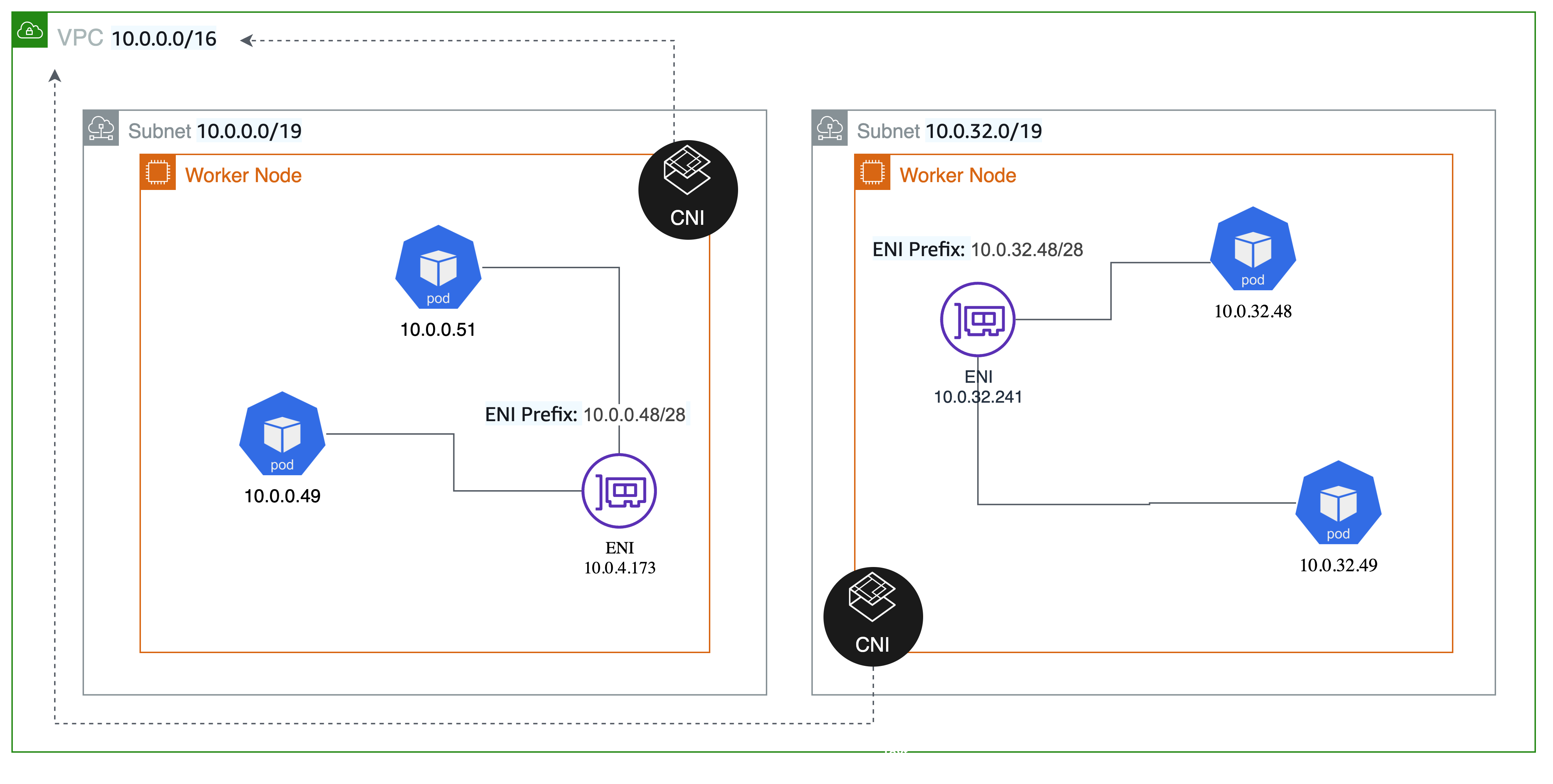
출처: https://trans.yonghochoi.com/translations/aws_vpc_cni_increase_pods_per_node_limits.ko
또한, 추가로 VPC-CNI에서는 노드와 파드의 IP 대역을 분리할 수 있는 기능도 제공한다. 관련 Docs 하지만, 이것은 vpc-cni의 장점과는 상반된다. 파드는 그대로 노드의 ENI를 사용하여 외부와 통신하겠지만, 노드의 서브넷과 파드의 서브넷이 구분된다. 그렇기에 LB에서 바로 파드의 IP로 라우팅하는 것 같이 외부에서 파드에 바로 접근하는 것이 힘들다. 하지만, 보안상이나 꼭 필요한 경우에만 사용하면 좋을 것 같다.
전략
앞에서 파드와 노드의 네트워크 대역이 같아져서 네트워크 비용을 절약할 수 있지만, 파드의 개수가 제한된다는 것을 확인했다. 이런 점 때문에 노드의 Spec이나 네트워크 대역을 신중히 설계해야 한다. 이때 실행될 서비스의 특성을 잘 파악해야한다. 리소스를 얼마나가져가고, 최대 어느정도의 파드가 필요할지 미리 파악하여 설계해야 문제가 없을 것 같다.
IPAM
L-IPAM
각 서버의 spec에 맞게 NIC이 추가되고, 하나의 NIC 당 POD의 IP pool(secondary IPs)가 할당된다. secondary ip를 통해 파드의 ip를 할당한다.
L-IPAM은 노드별로 보조 IP 주소의 warm-pool을 유지한다. 파드를 하나 추가할 때마다, warm-pool에서 사용가능한 IP를 가져와 파드에 할당한다. GitHub에서 자세한 내용을 확인할 수 있다.
- 흐름도: 파드가 생성 > kubelet > VPC CNI > L-IPAM에서 적절한 IP 할당 > kubelet에게 IP 제공
파드의 IP는 가장 앞단 ENI의 secondary pool을 모두 사용한 뒤, 다음 ENI를 추가하고 해당 pool을 사용한다.
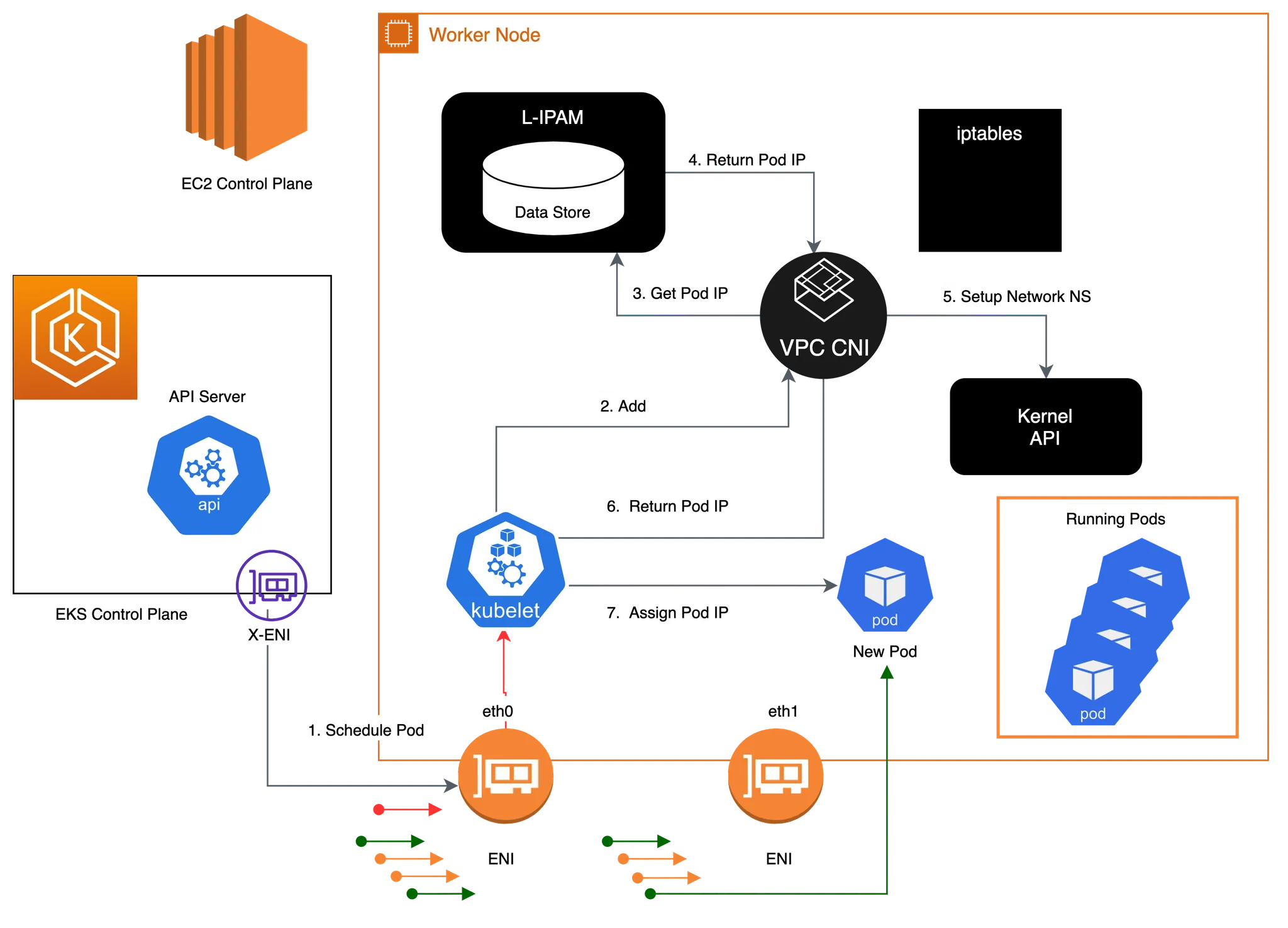
파드 통신
파드와 노드의 네트워크 대역이 같기에, 별도의 세팅이 필요없다. 기본적인 라우팅을 따라간다. 예를 들어, 특정 파드로 라우팅이 필요하면 파드의 subnet의 위치를 찾고, 해당 파드의 IP는 노드의 secondary IP이므로 노드로 진입한다. 노드로 진입하면 파드의 IP 인터페이스로 라우팅된다. 별다른 작업이 필요없다.
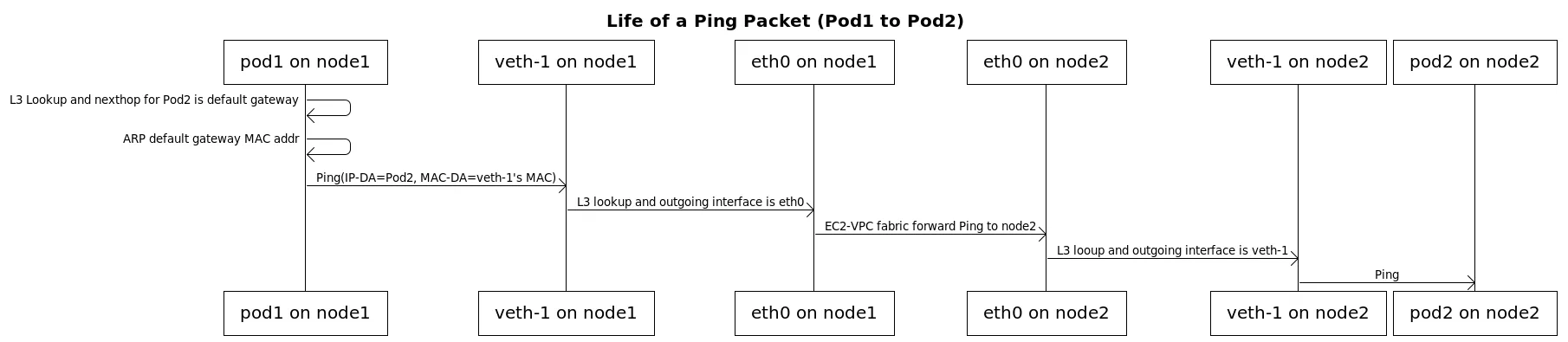
출처: https://github.com/aws/amazon-vpc-cni-k8s/blob/master/docs/cni-proposal.md
다른 노드 내의 파드
다른 노드와 통신할 때도, 위의 상황과 같다. 별다른 작업없이 기존의 AWS 라우팅 방식을 이용한다. 다른 CNI의 경우 노드와 파드의 대역이 달라 NAT 혹은 별도의 터널링이 필요했지만 vpc-cni에선 필요없다.
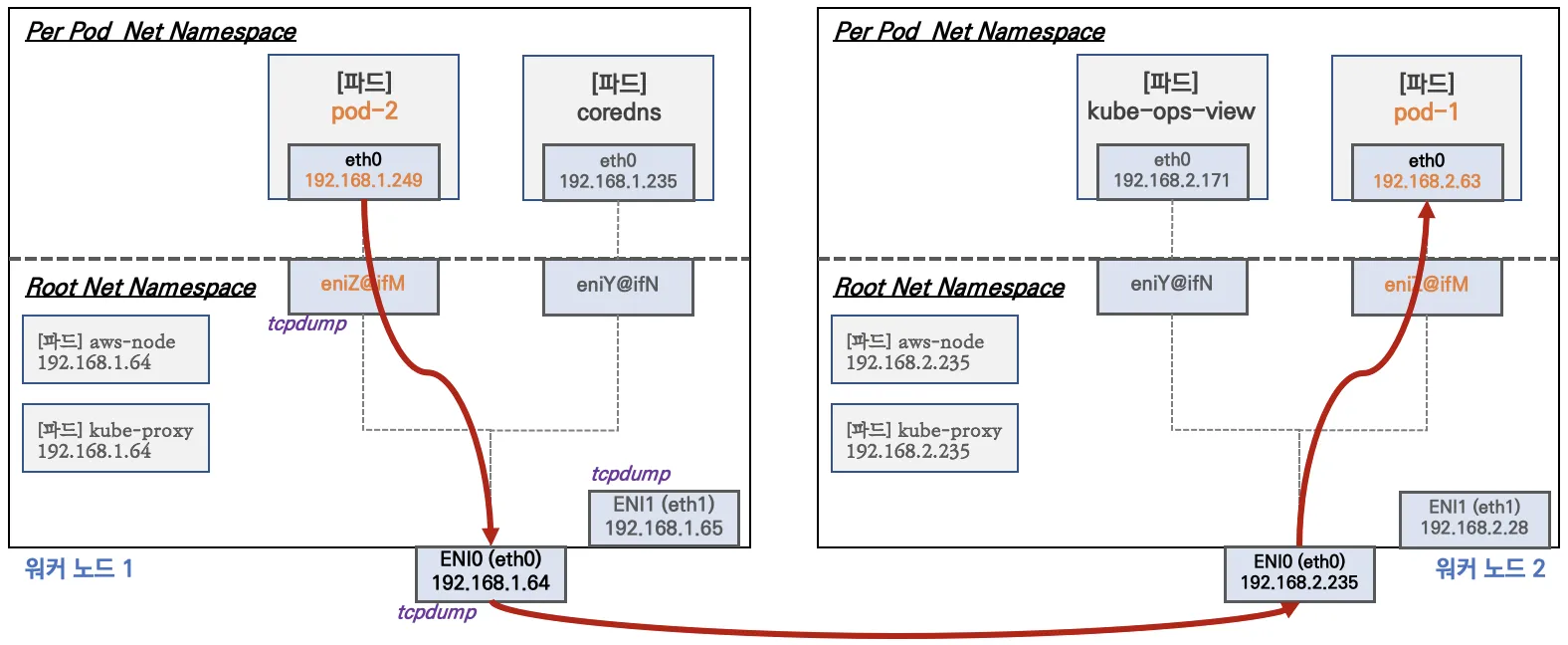
외부와의 통신
외부 통신시 노드의 IP로 SNAT을 진행한다. 만약, 회사와 Direct Connect를 구성하는 등 필요에 의해 SNAT 설정을 꺼두면 SNAT없이 파드의 IP로 진행한다.
VPC-CNI에서 default인 경우 SNAT은 iptables를 통해 진행한다.
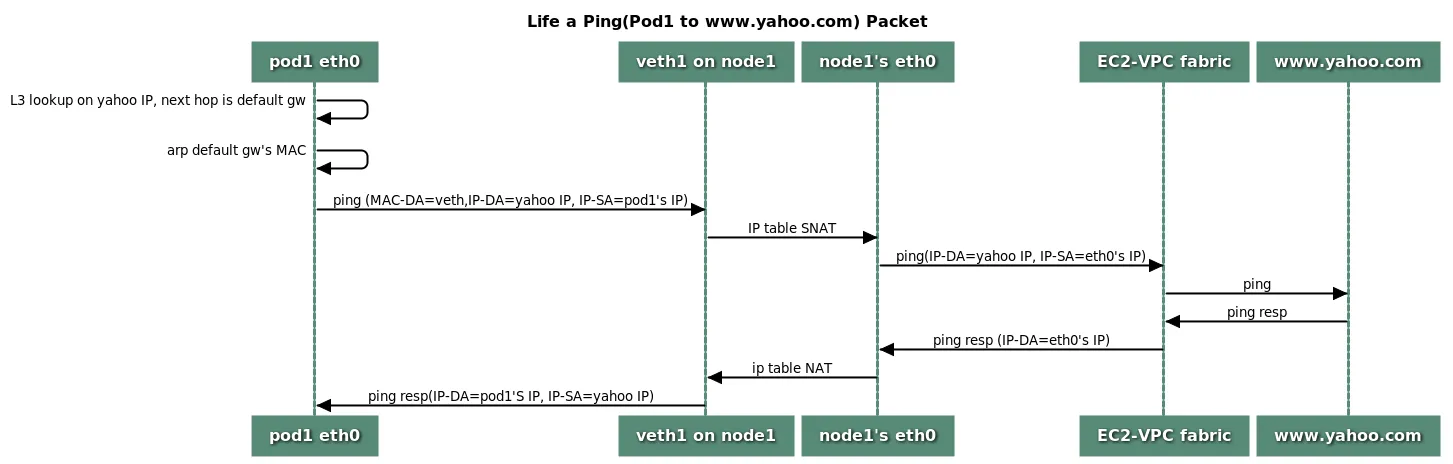
출처: https://github.com/aws/amazon-vpc-cni-k8s/blob/master/docs/cni-proposal.md
AWS Load Balancer
Load Balancer Controller 배포
우선 Helm을 통해 AWS Load Balancer Controller를 배포한다.
1
2
3
helm repo add eks https://aws.github.io/eks-charts
helm repo update
helm install aws-load-balancer-controller eks/aws-load-balancer-controller -n kube-system --set clusterName=$CLUSTER_NAME
AWS Load Balancer Controller는 알아서 API 서버를 통해 상태 변화를 읽고, LB 타입 서비스에 대한 외부 LB 연결 및 처리를 진행해준다. 정책이나 기능 관련 설정은 annotation을 통해 진행한다.
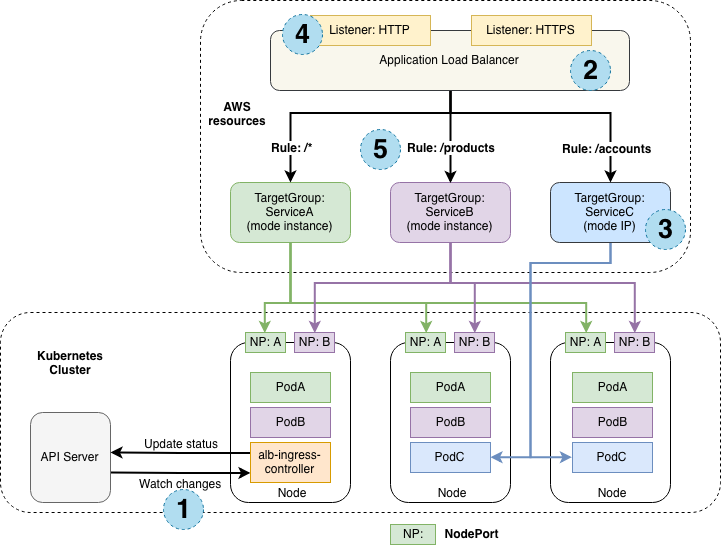
출처: https://kubernetes-sigs.github.io/aws-load-balancer-controller/v2.1/how-it-works/
NLB
NLB는 AWS의 L4 계층의 LB이다. 우리는 NLB를 통해 외부의 접속이 들어오면 LB에서 바로 파드로 라우팅하는 실습을 진행해본다. NLB IP 모드로 동작하여 파드로 by pass된다. 로드밸런서가 worker node group과 같은 VPC에 존재하기에 이것이 가능하다.
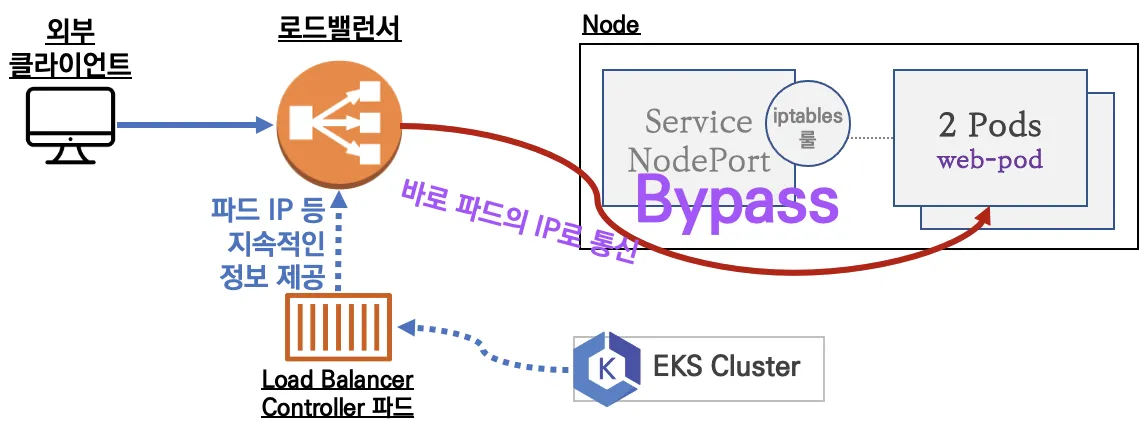
실습
실습을 위해 아래의 파일을 다운받고 리소스를 배포한다.
1
2
3
curl -s -O https://raw.githubusercontent.com/gasida/PKOS/main/2/echo-service-nlb.yaml
cat echo-service-nlb.yaml
kubectl apply -f echo-service-nlb.yaml
배포 확인

NLB 확인
Load Balancer Controller에 의해 바로 NLB가 붙는 모습이다.

AWS CLI를 통해 Target Group을 확인해보면, 노드의 IP가 아닌 파드의 IP가 보이는 것을 알 수 있다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
aws elbv2 describe-target-health --target-group-arn $TARGET_GROUP_ARN | jq
{
"TargetHealthDescriptions": [
{
"Target": {
"Id": "192.168.3.105",
"Port": 8080,
"AvailabilityZone": "ap-northeast-2c"
},
"HealthCheckPort": "8080",
"TargetHealth": {
"State": "healthy"
},
"AdministrativeOverride": {
"State": "no_override",
"Reason": "AdministrativeOverride.NoOverride",
"Description": "No override is currently active on target"
}
},
{
"Target": {
"Id": "192.168.2.95",
"Port": 8080,
"AvailabilityZone": "ap-northeast-2b"
},
"HealthCheckPort": "8080",
"TargetHealth": {
"State": "healthy"
},
"AdministrativeOverride": {
"State": "no_override",
"Reason": "AdministrativeOverride.NoOverride",
"Description": "No override is currently active on target"
}
}
]
}
당연히 해당 Target 정보를 콘솔에서도 아래와 같이 확인할 수 있다.

테스트
Health check 기간을 늘리고, 해당 worker 노드에서 tcpdump를 진행하면 아래와 같이 파드의 IP로 바로 패킷이 들어온다.

NLB 엔드포인트 반영 확인
파드의 replica를 변경해서 NLB에서 얼마나 빠르게 엔드포인트를 변경하는지 테스트해본다.
deploy replica를 1로 설정하고 테스트(거의 바로 반영된다)

deploy replica를 3으로 설정하고 테스트(반영하는데 약 30초 정도의 시간이 필요하다.)

Pod rediness gate
readinessGates를 설정하여 kubelet이 파드의 상태에 대해 평가하는 추가 조건 목록을 지정한다. readiness gate는 파드의 status.condition 필드의 현재 상태에 따라 결정된다. 이를 통해 우리는 파드의 상태를 더 면밀하게 볼 수 있다.
EKS에서 내부 동작은 mutating 기능을 통해 선택한 네임스페이스에서 readinessGates를 추가하는 방식으로 진행된다.
실습
1
2
kubectl apply -f echo-service-nlb.yaml
kubectl scale deployment deploy-echo --replicas=1
mutating 설정 확인
1
2
3
4
5
6
7
kubectl get mutatingwebhookconfigurations aws-load-balancer-webhook -o yaml | kubectl neat | grep namespaceSelector -A4
namespaceSelector:
matchExpressions:
- key: elbv2.k8s.aws/pod-readiness-gate-inject
operator: In
values:
이런 경우 mutating이 완료되기 위해 파드를 재생성해야 한다. admission controller는 API 서버 인증/인가 단계에서 처리가 되므로 이미 실행중인 파드의 작업을 진행하진 않는다.
파드를 재생성하고 관련 정보를 확인한다.
정상적으로 condition에 target-health.elbv2가 붙은 것을 볼 수 있다.
1
2
3
kubectl get pod -o yaml | grep target-health
- conditionType: target-health.elbv2.k8s.aws/k8s-default-svcnlbip-fb3dc30228
type: target-health.elbv2.k8s.aws/k8s-default-svcnlbip-fb3dc30228
Proxy Protocol v2
NLB를 사용하면 한번 NAT 되므로 클라이언트 IP를 잃어버린다. 하지만, Proxy Protocol v2를 사용하면 Client Ip를 보존할 수 있다. 헤더를 추가해서, 클라이언트 IP를 주는 방식이기에 엔드포인트 파드에서도 이를 받을 수 있도록 설정해야 한다.
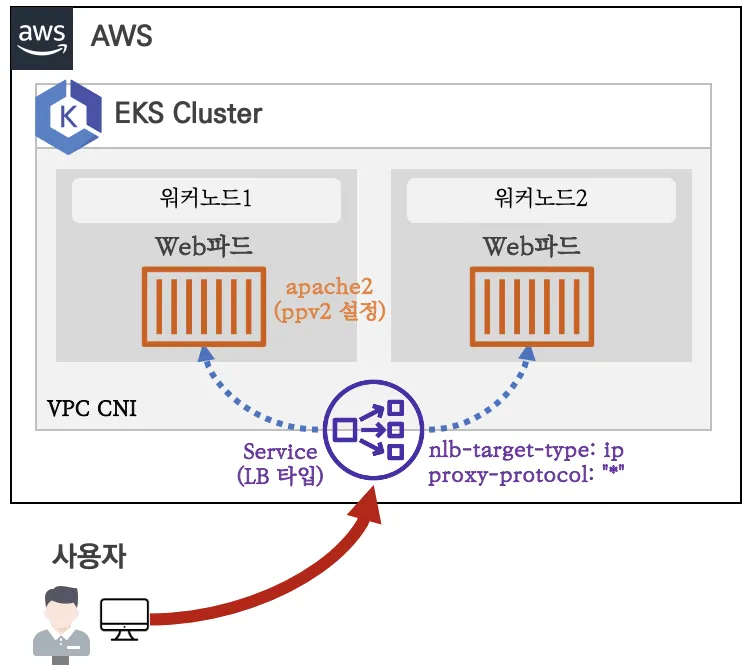
Topology Aware Routing
AWS EKS에서 multi AZ 네트워크 통신 비용도 규모가 커지면 상당히 비싸다. 실제 온프렘에서도 같은 Rack에 위치한 서버끼리 통신하면 네트워크 최적화가 가능하다. Kubernetes에서는 Topology Aware Routing을 제공한다. 이를 기반으로 같은 Zone끼리만 통신한다.
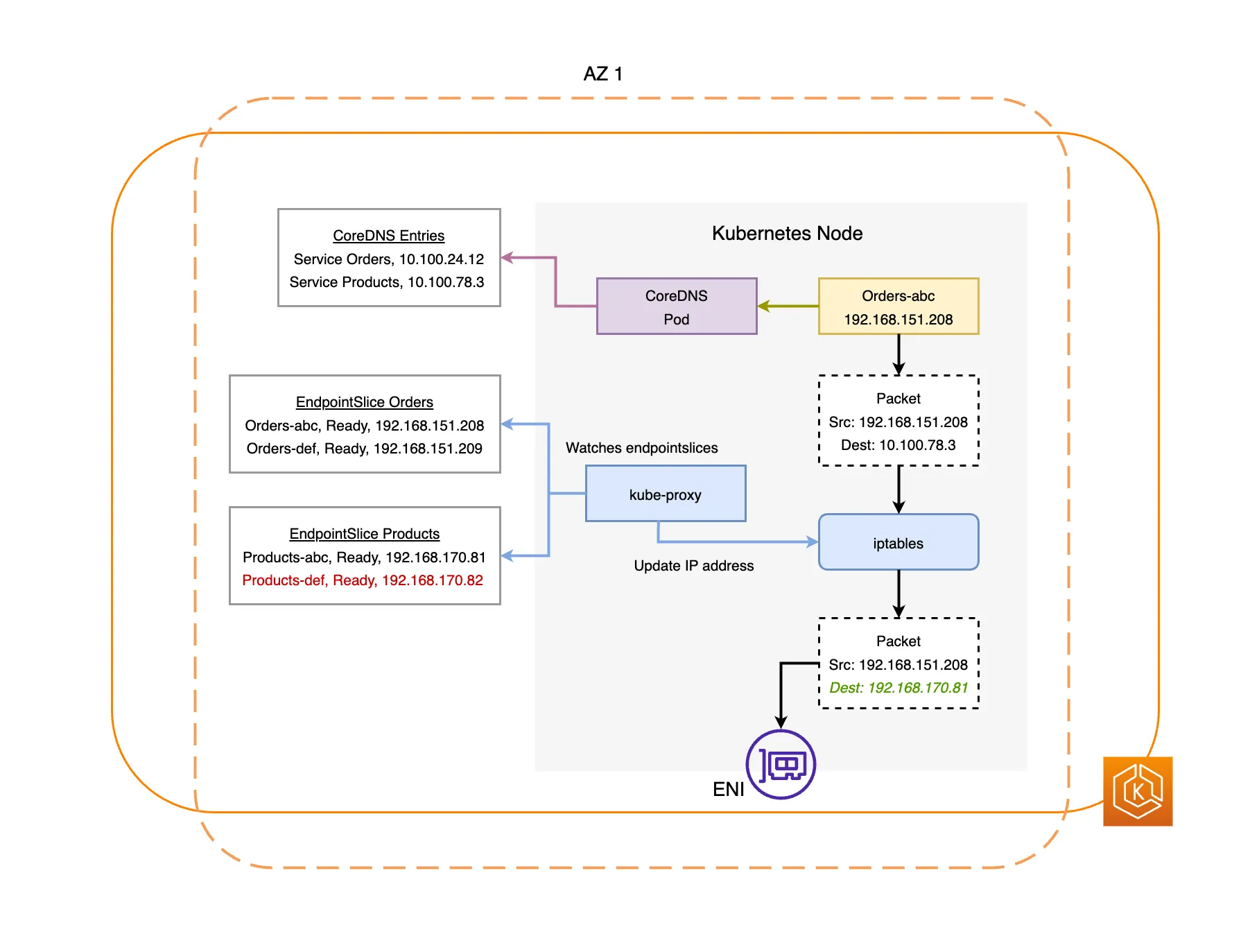
방식
hints와 zone을 통해 라우팅하고, 이를 기반으로 iptables가 각 워커노드에 대해 룰을 설정한다. iptables chain을 통해 해당 노드에 존재하는 파드로만 라우팅하도록한다.
문제상황
해당 노드에 목적지 파드가 없다면? Await, hints 정보를 지우고 다른 노드에 있는 파드로 라우팅하도록 룰을 설정한다.
실습 진행
실습 리소스
아래의 명령어를 그대로 실행하여, 3개의 파드와 파드에 대한 서비스를 생성한다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
cat <<EOF | kubectl apply -f -
apiVersion: apps/v1
kind: Deployment
metadata:
name: deploy-echo
spec:
replicas: 3
selector:
matchLabels:
app: deploy-websrv
template:
metadata:
labels:
app: deploy-websrv
spec:
terminationGracePeriodSeconds: 0
containers:
- name: websrv
image: registry.k8s.io/echoserver:1.5
ports:
- containerPort: 8080
---
apiVersion: v1
kind: Service
metadata:
name: svc-clusterip
spec:
ports:
- name: svc-webport
port: 80
targetPort: 8080
selector:
app: deploy-websrv
type: ClusterIP
EOF
iptables 확인
이제 worker 노드에 들어가서 iptables 룰을 확인한다. svc IP를 통해 필터링하여 체인을 찾아낸 뒤, 체인에 대한 정보를 확인한다.
각 파드로 약 1/3의 확률로 공평하게 분산되는 것을 확인할 수 있다.

Topology Aware 설정
아래의 명령어를 통해 어노테이션으로 topology-mode를 변경한다.
1
2
3
kubectl annotate service svc-clusterip "service.kubernetes.io/topology-mode=auto"
service/svc-clusterip annotated
이제 client pod에서 서비스에 접근하면, 나와 같은 노드에 있는 파드로만 라우팅된다.
1
2
3
4
kubectl exec -it netshoot-pod -- zsh -c "for i in {1..100}; do curl -s svc-clusterip | grep Hostname; done | sort | uniq -c | sort -nr"
100 Hostname: deploy-echo-859cc9b57d-xf6rp
엔드포인트 확인
엔드포인트를 확인하면, hints를 통해 클라이언트의 서브넷과 일치하는 파드로 라우팅하도록 설정되어있다.
1
2
3
4
5
6
7
8
9
10
11
12
kubectl get endpointslices -l kubernetes.io/service-name=svc-clusterip -o yaml | grep hints -A2
hints:
forZones:
- name: ap-northeast-2b
--
hints:
forZones:
- name: ap-northeast-2a
--
hints:
forZones:
- name: ap-northeast-2c
설정변경 후 iptables 다시 확인
iptables를 확인하면, 아까와는 다르게 1개의 파드(현 노드에 있는)로만 라우팅하는 체인만 존재한다.

Network Policies
“Amazon VPC CNI now supports Kubernetes Network Policies” 이제 vpc-cni에서도 network policy를 완전하게 지원한다고 한다. cilium에서 봤던 eBPF를 통해 vpc-cni에서도 패킷 필터링을 진행한다고한다.
실습 진행
eks workshop에 존재하는 실습 파일을 다운받고, 배포를 진행한다.
1
2
3
4
git clone https://github.com/aws-samples/eks-network-policy-examples.git
cd eks-network-policy-examples
tree advanced/manifests/
kubectl apply -f advanced/manifests/
원래 vpc-cni addon에 networkpolicy 설정을 업데이트해야 하지만, 가시다님의 배포파일에 NetworkPolicy 옵션을 설정해주셨다.
1
2
cat myeks.yaml | grep NetworkPolicy
enableNetworkPolicy: "true"
모든 트래픽 거부
모든 트래픽을 거부하는 네트워크 정책을 적용한다.
1
kubectl apply -f advanced/policies/01-deny-all-ingress.yaml
아래의 사진과 같이 클라이언트 파드에서 통신 연결시 실패하는 모습을 볼 수 있다.
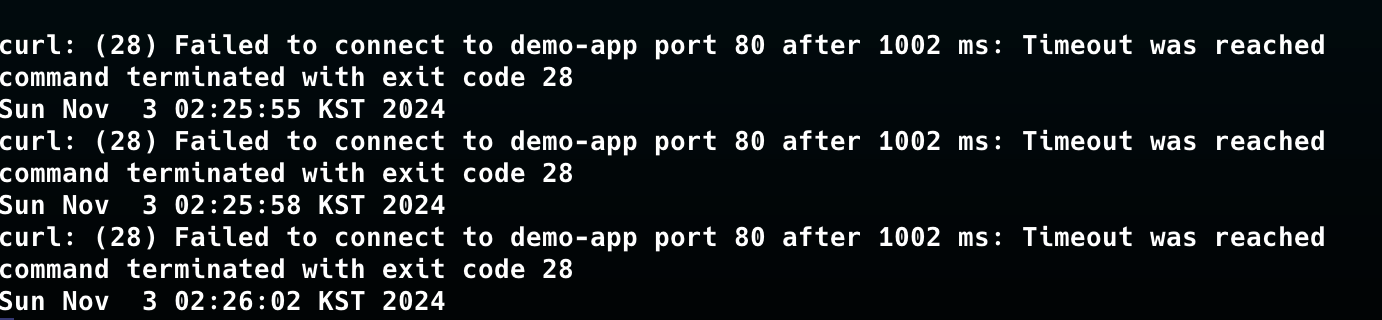
이제 ebpf 관련 자료를 살펴보자.
우선 ebpf map을 살펴보면, 맵이 늘어난 것을 볼 수 있다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
for i in $N1 $N2 $N3; do echo ">> node $i <<"; ssh ec2-user@$i **sudo /opt/cni/bin/aws-eks-na-cli ebpf loaded-ebpfdata**; echo; done
>> node 192.168.1.98 <<
PinPath: /sys/fs/bpf/globals/aws/programs/demo-app-786dbc7dfc-default_handle_egress
Pod Identifier : demo-app-786dbc7dfc-default Direction : egress
Prog ID: 10
Associated Maps ->
Map Name: policy_events
Map ID: 6
Map Name: aws_conntrack_map
Map ID: 5
Map Name: egress_map
Map ID: 8
========================================================================================
PinPath: /sys/fs/bpf/globals/aws/programs/demo-app-786dbc7dfc-default_handle_ingress
Pod Identifier : demo-app-786dbc7dfc-default Direction : ingress
Prog ID: 9
Associated Maps ->
Map Name: aws_conntrack_map
Map ID: 5
Map Name: ingress_map
Map ID: 7
Map Name: policy_events
Map ID: 6
========================================================================================
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
for i in $N1 $N2 $N3; do echo ">> node $i <<"; ssh ec2-user@$i sudo /opt/cni/bin/aws-eks-na-cli ebpf progs; echo; done
>> node 192.168.1.98 <<
Programs currently loaded :
Type : 26 ID : 6 Associated maps count : 1
========================================================================================
Type : 26 ID : 8 Associated maps count : 1
========================================================================================
Type : 3 ID : 9 Associated maps count : 3
========================================================================================
Type : 3 ID : 10 Associated maps count : 3
========================================================================================
>> node 192.168.2.242 <<
Programs currently loaded :
Type : 26 ID : 6 Associated maps count : 1
========================================================================================
Type : 26 ID : 8 Associated maps count : 1
========================================================================================
>> node 192.168.3.127 <<
Programs currently loaded :
Type : 26 ID : 6 Associated maps count : 1
========================================================================================
Type : 26 ID : 8 Associated maps count : 1
========================================================================================
이제 한번 정책을 지워본다.
1
kubectl delete -f advanced/policies/01-deny-all-ingress.yaml
정책 삭제 후 깔끔하게 ebpf 관련 내용이 정리된 모습이다. 이를 통해 ebpf를 통해 필터링을 진행한다는 것을 다시금 확인할 수 있었다.
1
2
3
4
5
6
7
for i in $N1 $N2 $N3; do echo ">> node $i <<"; ssh ec2-user@$i sudo /opt/cni/bin/aws-eks-na-cli ebpf loaded-ebpfdata; echo; done
>> node 192.168.1.98 <<
>> node 192.168.2.242 <<
>> node 192.168.3.127 <<
마치며
EKS 네트워크를 마지막으로 KANS 스터디의 공식적인 과정은 끝났다. 스터디를 시작하기전엔 Cilium, Istio에 대해 아주 얇은 수준에 지식만 있었는데, 이제 저것이 어떤 부분에 좋고 어떻게 네트워크 통신을 제어하는지 자신있게 설명할 수 있을 것 같다. (이번 스터디를 공식문서를 정말 많이보게 되어 조금 자신감이 생겼다.)
하지만, 아직 제공해주신 좋은 문서들을 전부 보지 못했기에 앞으로 한달정도 기간을 가지며 체하지 않게 차근차근 삼키는 과정이 필요할 것으로 보인다. 그동안 스터디 자료, 다른 분의 과제 포스팅을 보면서도 많이 배우고 성장했던 좋은 시간이었다.
스터디 장이신 가시다님 덕분에 좋은 스터디를 함께 수 있었고, 많이 배울 수 있었습니다. 또, 다른 스터디원분들도 좋은 포스팅 작성해주셔서 감사합니다. 🙇♂️