한 페이지에 Cpp 모두 정리하기
한 페이지로 끝내는 C++ 문법
C++ vs C
C++은 객체지향적 언어인 Simula의 개념을 C언어에 추가하여 만든 프로그래밍언어이다.
제네릭, 객체지향, 구조적 프로그래밍이 가능하다는 장점이 있다.
코드 실행 방식
소스코드가 실행파일이 되어야, 실행할 수 있다.
- 선행처리기: “#” 문자로 시작하는 선행처리 지시문(#define)을 처리한다. 컴파일러가 작업하기 좋도록 소스를 재구성하는 역할을 한다.
- 컴파일러: 소스코드를 기계어로 변환한다.(
.o,.obj) - 링커: 오브젝트 파일과 라이브러리 파일, 시동코드(OS와의 인터페이스를 담당함)를 합쳐 하나의 실행 파일을 만든다.
우리는 링커에서 만들어진 실행파일을 통해 프로그램을 실행할 수 있다.
vscode에서 Code Runner를 통해 Cpp 파일을 실행시키면 터미널에서 자동으로 다음과 같은 명령어가 입력된다.
1
2
cd "/Users/kane/workspace/1. Project/Algorithm/백준/9345/" && g++ -
std=c++2a -g code.cpp -o a.out && "/Users/kane/workspace/1. Project/Algorithm/백준/9345/"/a.out
이를 단계별로 분석하면, 디렉터리를 작업 환경으로 옮기고 g++ 컴파일러를 통해 코드를 읽어 a.out 실행파일을 만든다. 이후 해당 실행파일을 실행시킨다.
타입 변환
- 묵시적 변환
만약, 서로 다른 타입으로 연산을 진행하면, 결과물의 타입은 더 범위가 큰 쪽으로 변환된다. 산술 연산 시에는 데이터의 손실이 최소화되는 방향으로 묵시적 타입 변환이 진행됩니다.
- 명시적 변환
- (변환할타입) 변환할데이터 // C언어와 C++ 둘 다 사용 가능함.
- 변환할타입 (변환할데이터) // C++에서만 사용 가능함.
static
정적 변수를 의미하고, 이는 함수의 호출이 끝나도 사라지는 지역 변수와는 다르게 지속적으로 메모리 공간을 유지한다.
- 같은 이름의 변수 접근 순위
먼저 가까운 블락단위에 생성된 지역 변수에서부터 점점 멀리나간다. 즉 같은 이름으로 선언된 지역변수와 전역변수가 있으면 지역변수를 사용하게 된다.
Auto
C++11 버전에서 생겨났고, 컴파일러 단계에서 자동으로 타입을 할당한다. 시험에서는 편하지만, 타입이 헷갈릴 때는 쓰지 않는 것이 좋다.
상수표현
- 리터럴 상수: 말그대로, 숫자를 의미하며 C++에서 숫자들은 상수로 표현된다. ex) 1.1 or 3
- 심볼릭 상수: 앞에 const를 붙여 상수처럼 사용한다. 선언과 동시에 초기화하며, 값을 수정할 수 없다.
심볼릭 상수는 아래와 같이 값이 변경되면 안될 때 사용한다. 주로 for, 함수 등 파라미터로 넘겨줄 때나 사이즈와 같은 변수를 지정할 때 사용한다.
1
2
3
bool operator>(const Entry &lhs, const Entry &rhs) {
return lhs.time > rhs.time;
}
연산자
- 논리연산자
논리는 &&, ||, !가 있다는 것만 기억하면 된다.
- 비트연산자
| & | 대응되는 비트가 모두 1이면 1을 반환함. (비트 AND 연산) | |
|---|---|---|
| 대응되는 비트 중에서 하나라도 1이면 1을 반환함. (비트 OR 연산) | ||
| ^ | 대응되는 비트가 서로 다르면 1을 반환함. (비트 XOR 연산) | |
| ~ | 비트를 1이면 0으로, 0이면 1로 반전시킴. (비트 NOT 연산, 1의 보수) | |
| « | 지정한 수만큼 비트들을 전부 왼쪽으로 이동시킴. (left shift 연산) | |
| » | 부호를 유지하면서 지정한 수만큼 비트를 전부 오른쪽으로 이동시킴. (right shift 연산) |
- 삼항연산자(조건식 ? 반환값1 : 반환값2)
- 포인터 연산자
선언: 포인터는 주소를 가리킨다.
1
int* ptr = #
- 주소연산자(&): &은 참조 변수로도 사용된다.
- 참조연산자(*)
- 포인터 연산(++, —): 해당 포인터의 타입의 크기만큼 증가, 감소한다.(ex. int 형이면 4바이트만큼)
배열과 포인터
배열과 포인터는 서로 대체할 수 있다. 배열의 이름은 포인터와 거의 유사하다. 상수라는 점(다른 배열을 대입할 수 없다는 점) ex) arr1 ≠ arr2 을 제외하고는 똑같다. 배열의 이름을 가지고 포인터처럼 연산을 할 수 있다.
1
2
3
4
5
int arr[10]= {1,2,3,4,5,6,7,8,9,10};
int* ptr = arr;
// 위와 아래의 결과는 같다.
cout << *arr << '\n'<< *(arr + 9);
cout << *ptr << '\n'<< *(ptr + 9);
“배열 혹은 포인터와 관련된 연산을 할 때는 주의해야한다. 실제 사용하지 않는 메모리 영역(ex. 배열의 크기를 넘어선 접근)을 할 때 컴파일러는 오류를 발생시키지 않고 프로그램을 동작시킨다.”
전달 방식
[얇은 복사 vs 깊은 복사]
“단지 주소공간만 가르키는 가? 새로운 주소공간을 할당하는가?”가 기준이된다.
- 얇은 복사는 얕은 복사의 경우 동적 할당을 받은 변수의 주소값을 공유한다.
- 깊은 복사는 깊은 복사는 새로이 동적할당을 받고, 원본의 데이터를 복사한다.(완전히 다른 개별적인 객체가 된다.)
[call by value vs call by reference]
C언어에서 함수 파라미터 방식은 값에 의한 전달 방식을 따른다. 매개변수의 값만 복사한다. 만약 참조 연산자를 사용하면, 참조에 의한 전달을 진행한다.
Namespace
이름 충돌 문제를 C++에서는 네임스페이스(namespace)를 통해 해결하고 있다.
접근 방법: 네임스페이스에 접근하기 위해서는 범위 지정 연산자(::, scope resolution operator)를 사용하여, 해당 이름을 특정 네임스페이스로 제한하면 된다.
네임스페이스에 속한 이름을 사용할 때마다 매번 범위 지정 연산자를 사용하여 이름을 제한하는 것은 매우 불편하다. 또한, 길어진 코드로 인해 가독성 또한 떨어지게 된다.
C++에서는 이러한 불편함을 해소할 수 있도록 다음과 같은 방법을 제공하고 있다.
using 지시자(directive):
using namespace 네임스페이스이름;1
using namespace std;
using 선언(declaration):
using 네임스페이스이름::이름;1 2 3 4
using std::cout; int main() { cout << "Hello, World!" << std::endl; }
포인터 vs 참조(&)
포인터는 하나의 변수이다. 참조는 변수라고 보기에는 부족하다. 재바인딩이 불가능하다. 즉, 새로운 값으로 변경할 수 없다. 한번 참조할 변수(메모리)를 결정했으면 가리키는 메모리 공간을 변경할 수 없다는 뜻이다.
1
2
3
4
int x = 10;
int y = 10;
int& ref = x; // 참조 대상을 y로 바꾸거나 할 수 없다.
ref = 20;
시간복잡도
메모리
C언어 동적할당
C언어에서 메모리 할당 함수로 malloc, calloc, realloc이 존재한다.
malloc과 calloc은, void* 타입을 리턴하며 직접 캐스팅해야 한다.
- ex)
char* p = (char*) malloc(sizeof(char)*10);
malloc과 calloc의 차이점은 calloc은 사이즈를 입력으로 넣어주고 0으로 초기화해준다.
realloc은 위의 두가지 유형으로 메모리를 할당한 후 메모리공간을 늘리거나, 줄이고 싶을 때 사용한다. void* realloc(void* p, size_t size)
이렇게 생성한 공간은 프로그램이 종료될 때, 내가 직접 해제시켜야 한다. free()를 통해 해제한다.(PC를 끄기 전까지 해체하지 않으면 점유된다.)
realloc()의 대표적 문제는 정말 혹시나 메모리 할당이 실패할 경우 null이 반환되기 때문에 기존의 메모리가 할당되어 있는 포인터를 잃어버리는 것이다. 또한 여러 포인터가 주소공간을 공유하는 상황이라면, realloc 함수를 사용하면, 다른 포인터들은 이상한 곳을 가리키게 된다.
C++ 동적할당(New)
New를 통해서 동적할당을 진행한다. 타입* 포인터이름 = new 타입; 반환명령어는 delete 포인터이름; 아래는 장점 목록이다.
- 타입 안정성(자동으로 타입 변환)
- 예외 처리(실패하면 예외 처리, 반면 malloc은 NULL만 반환)
- 자동으로 사이즈 계산(sizeof 필요없음)
- 객체의 생성자를 호출(생성시 초기화 가능)
스마트 포인터
new, delete는 아래의 문제가 있다. 우리가 직접 관리해줘야한다는 불편한점이 있다.
메모리 누수: new로 할당한 메모리는 반드시 delete로 해제해야 하며 그렇지 않으면 메모리 누수가 발생한다.
이러한 주의사항들로 인해 C++11 이후에는 스마트 포인터(std::unique_ptr, std::shared_ptr 등)를 사용하는 것이 권장된다고 한다. 스마트 포인터는 자동 메모리 관리 기능을 제공하므로 위와 같은 문제를 해결할 수 있다.
구조체(struct)와 공용체(union)
구조체는 다양한 크기의 타입을 멤버 변수로 가질 수 있는 타입입니다. 구조체는 크기가 가장 큰 멤버 변수를 기준으로 모든 멤버 변수의 메모리 크기를 맞춘다. 이때 생기는 패딩을 바이트 패딩이라고 하며, 이때 추가되는 바이트를 패딩 바이트(padding byte)라고 합니다.
메모리 할당 규칙
- 가장 큰 멤버 변수를 기준으로 메모리 할당함
- 가장 작은 변수부터 연속적으로 메모리를 채움, 만약 현재 남은 메모리크기보다 타입의 크기가 크면 추가적으로 할당하고, 기존의 남은 크기를 패딩으로 채워넣음
공용체
공용체(union)는 union 키워드를 사용하여 선언하며, 대다수는 구조체와 같습니다. 하지만 모든 멤버 변수가 하나의 메모리 공간을 공유한다는 점만이 다르다. 크기가 가장 큰 멤버 변수의 크기로 메모리를 할당받습니다. 그렇기에 멤버 변수 하나만을 수정해도 다른 값들 또한 변경될 수 있다.
1
2
3
4
5
6
7
8
union ShareData
{
unsigned char a;
unsigned short b;
unsigned int c;
};
union ShareData data;
data.c = 0x12345678;
위 코드에서 a의 값은 0x78이 될 것이며, b의 값은 0x5678이 될 것입니다. 반대로 빅 엔디안 시스템에서는 결과가 다를 수 있다.
데이터 저장방식
ex) 0x12345678
두개로 끝은 것은 하나의 주소는 주로 바이트 단위이기 때문
- 리틀인디안: 낮은 주소에, 하위 비트가 넣어짐(즉 주소 순으로 표현하면 78,56,34,12)
- 빅인디안: 낮은 주소에, 상위 비트가 넣어짐(12,34,56,78)
리틀 엔디안 방식은 낮은 주소에 데이터의 낮은 바이트(LSB : Least Significant Byte)를 저장하는 방식이다. 이 방식은 평소 사람이 숫자를 사용하는 선형 방식과 반대로 거꾸로 읽어야 한다.
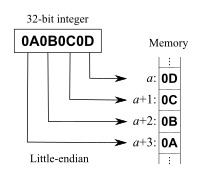
[출처: 위키피디아, https://ko.wikipedia.org/wiki/%EC%97%94%EB%94%94%EC%96%B8]
상속
접근제어
클래스안에 접근 제어 방식은 public, private, protected 3가지가 있다.
public: 접체 접근 가능private: 클래스 내부에서만 가능, 접근제어 키워드가 없으면 private가 기본값protected: 상속받은 “파생”클래스, 자신의 클래스 내부에서만 가능friend- friend 클래스는 friend로 선언된 다른 클래스의 private 및 protected 멤버에 접근할 수 있다.
- friend 함수는 private 및 protected 멤버에 접근할 수 있는 권한을 부여할 수 있다.
오버로딩과 오버라이딩
오버라이딩은 동적으로 실제 그 객체의 타입에 맞는 함수를 실행하는 것이고, 오버로딩은 정적으로 매개변수에 맞는 함수를 선택하여 실행하는 것이다.
virtual이란?
virtual은 C++의 다형성을 구현하기 위한 키워드로 abstract method이다. 이를 통해 파생클래스에서 오버라이딩될 수 있다.
virtual 함수를 호출하면, 컴파일러는 객체의 타입이 아닌 참조를 통해 가리키는 실제 객체의 타입을 확인하여 적절한 함수를 호출한다. 내부적으로는 가상 함수 테이블을 사용하여, 현재의 타입이 아닌 실체를 맵핑한다. 아래의 코드에서 (1)의 경우에서 Base 타입의 함수가 아닌 실체의 함수 Derived show, display를 맵핑한다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
class Base {
public:
virtual void show() { cout << "Base class show function" << endl; }
virtual void display() { cout << "Base class display function" << endl; }
};
class Derived : public Base {
public:
void show() override { cout << "Derived class show function" << endl; }
void display() override { cout << "Derived class display function" << endl; }
};
int main() {
**(1)**Base* basePtr = new Derived();
}
업캐스팅과 다운캐스팅
업캐스팅 = 하위 타입에서 상위 타입으로 참조하는 것이다. 다운 캐스팅은 반대로 상위에서 하위로 참조한다. 업캐스팅은 안전하나, 다운캐스팅은 불완전하다. 탈 것이라는 상위타입에서 자동차라는 하위타입으로 캐스팅하면, 만약 실체가 비행기라면 오류가 발생한다.
1
2
Derived d;
Base* ptr = &d; // 업캐스팅
String
C++의 std::string 클래스와 C 스타일 스트링 간의 주요 차이점은 아래와 같다.
- C 스타일 스트링: 문자들의 배열로, 널(
'\0') 문자로 종료된다. 예:char myStr[] = "Hello";마지막 문자열에 널 문자가 입력된다. - std::string: C++ 표준 라이브러리의 클래스로서, 문자들의 동적 배열과 관련된 메서드들로 구성된다.
- 크기조절: C스타일은 불가능하지만, C++ 스타일은 가능하다. 내부적으로 메모리 관리를 한다.
1
2
3
4
5
6
char string1[5] = "1234";
printf("%s", string1);
abc[3] = '\0';
printf("%s", string1);
// 에러 발생, 크기를 넘어섬 (12345'\0') 총 6개의 문자가 대입되기에, 크기를 넘어섬
char string2[5] = "12345";
인라인 함수
위와 같이 C++에서 함수의 호출은 꽤 복잡한 과정을 거치므로, 약간의 시간이 걸리게 됩니다. 하지만 함수의 실행 시간이 매우 짧다면, 함수 호출에 걸리는 시간도 부담이 될 수 있다.
인라인 함수는 호출될 때 일반적인 함수의 호출 과정을 거치지 않고, 함수의 모든 코드를 호출된 자리에 바로 삽입하는 방식의 함수이다. 이 방식은 함수를 호출하는 데 걸리는 시간은 절약되나, 재귀와 같은 함수의 여러 이점을 사용할 수 없다.
인라인 함수 사용시 단점은 컴파일 시간(인라인 함수 치환) 증가, 디버깅 시간 증가, 재귀 불가능이 있다.
함수 포인터
함수 포인터는 말 그대로 함수를 가리키는 포인터다. 프로그램에서 정의된 함수는 프로그램이 실행될 때 모두 메인 메모리에 올라가며 함수 포인터는 함수의 첫 주소를 가리킨다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
**double (*calc)(double, double) = NULL; // 함수 포인터 선언**
double num1 = 3, num2 = 4, result = 0;
char oper = '*';
switch (oper)
{
case '+' :
calc = Add;
break;
case '-':
calc = Sub;
break;
case '*':
calc = Mul;
break;
case '/':
calc = Div;
break;
default:
cout << "사칙연산(+, -, *, /)만을 지원합니다."; }
break;
}
STL
그외
volatile 키워드를 통해 컴파일러에게 최적화를 제한하는 용도로 사용한다. voliatile로 선언한 변수는 컴파일러가 해당 변수를 최적화에서 제외하여 항상 메모리에 접근하도록 하는 키워드입니다.
아래와 같은 경우 컴파일러는 두번째 코드로 해석하여 최적화한다. 이를 방지하기 위해 volatile 키워드를 사용한다.
[기존 코드]
1
2
3
4
5
6
7
8
static int foo;
void bar(void)
{
foo = 0;
while (foo != 255);
}
[컴파일러가 최적화한 코드]
1
2
3
4
5
6
void bar_optimized(void)
{
foo = 0;
while (true);
}
초기화
이거는 다른 블로그를 참고하다가 발견한 것이다. 게임 회사 면접에서 아래와 같이 초기화 방법을 물어봤다고 한다. 몰랐던 사실인데 아래와 초기화를 진행하면 연산이 하나로 줄어든다고 한다.
- 생성후 초기화
1
2
3
4
5
Car() {
바퀴 = 4;
엔진 = 1;
기름 = 0;
}
- 생성시 초기화
1
2
3
Car() : 바퀴(4), 엔진(1), 기름(0) {
}
생성후 초기화가 한번에 진행하고, 생성시 초기화는 한번의 연산과정이 더 필요하니 비용이 2배라고 한다.
참고자료
https://tcpschool.com/c/c_intro_programming
https://velog.io/@mardi2020/C-면접-질문-정리
https://se-jung-h.tistory.com/entry/C-C-기술-면접-질문
https://www.hanbit.co.kr/channel/category/category_view.html?cms_code=CMS1726560277&cate_cd=