MetalLB 알아보기
MetalLB 알아보기
💡 KANS 스터디
CloudNet에서 주관하는 KANS(Kubernetes Advanced Networking Study)으로 쿠버네티스 네트워킹 스터디입니다. 아래의 글은 스터디의 내용을 기반으로 작성했습니다.스터디에 관심이 있으신 분은 CloudNet Blog를 참고해주세요.
들어가며
4주차에서는 Service 리소스의 배경과 ClusterIP, NodePort, LB Type에 대해 간략하게 살펴보고 ClusterIP와 NodePort에 대해 자세하게 알아봤다. 여기서는 LB Type에 대해 자세히 알아보고 MetalLB로 실습을 진행한다.
Load Balancer Type
로드밸런서 타입은 클라우드 제공자가 지원하는 로드밸런서와 연동되는 서비스 타입이다. 온프레미스에서는 구성하기 힘들다는 제약이 있다.
로드밸런서 타입 장점은 아래와 같다.
Failover
외부 로드밸런서와 연동시, Health Check를 통해 노드의 상태를 파악하고 엔드포인트에서 제거 및 생성할 수 있다.
트래픽 분산
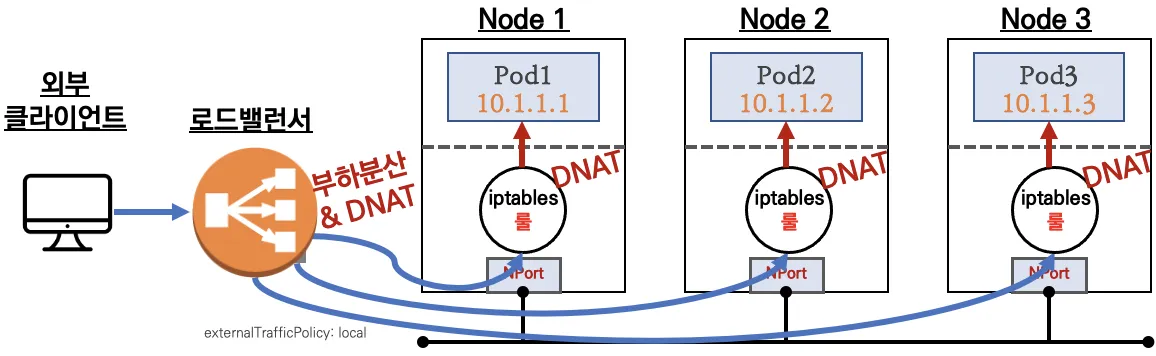
- 로드밸런서를 통해 특정 노드로 계속 인입되는 것이 아닌 모든 노드에 골고루 트래픽이 분산된다.
externalTrafficPolicy설정을 통해 들어온 노드에 있는 파드로 라우팅하여 최적화할 수 있다.- 클라우드에서 동작할 경우, 제공하는 CNI를 통해 네트워크 홉을 최적화할 수 있다.
예를 들어, VPC-CNI의 경우 파드와 노드의 네트워크 대역이 같기에 로드밸런서에서 바로 파드로 라우팅할 수 있다.
보안
NodePort로 노출할 경우, Worker Node의 IP를 외부로 노출하니 보안적으로 좋지 않다. Load Balancer를 통해서 이를 개선할 수 있다.
실습 환경
아래의 YAML을 통해 AWS EC2 혹은 자신의 컴퓨터에서 kind 기반 클러스터를 구축할 수 있습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
kind: Cluster
apiVersion: kind.x-k8s.io/v1alpha4
featureGates:
"InPlacePodVerticalScaling": true #실행 중인 파드의 리소스 요청 및 제한을 변경할 수 있게 합니다.
"MultiCIDRServiceAllocator": true #서비스에 대해 여러 CIDR 블록을 사용할 수 있게 합니다.
nodes:
- role: control-plane
labels:
mynode: control-plane
topology.kubernetes.io/zone: ap-northeast-2a
extraPortMappings: #컨테이너 포트를 호스트 포트에 매핑하여 클러스터 외부에서 서비스에 접근할 수 있도록 합니다.
- containerPort: 30000
hostPort: 30000
- containerPort: 30001
hostPort: 30001
- containerPort: 30002
hostPort: 30002
- containerPort: 30003
hostPort: 30003
- containerPort: 30004
hostPort: 30004
kubeadmConfigPatches:
- |
kind: ClusterConfiguration
apiServer:
extraArgs: #API 서버에 추가 인수를 제공
runtime-config: api/all=true #모든 API 버전을 활성화
controllerManager:
extraArgs:
bind-address: 0.0.0.0
etcd:
local:
extraArgs:
listen-metrics-urls: http://0.0.0.0:2381
scheduler:
extraArgs:
bind-address: 0.0.0.0
- |
kind: KubeProxyConfiguration
metricsBindAddress: 0.0.0.0
- role: worker
labels:
mynode: worker1
topology.kubernetes.io/zone: ap-northeast-2a
- role: worker
labels:
mynode: worker2
topology.kubernetes.io/zone: ap-northeast-2b
- role: worker
labels:
mynode: worker3
topology.kubernetes.io/zone: ap-northeast-2c
networking:
podSubnet: 10.10.0.0/16 #파드 IP를 위한 CIDR 범위를 정의합니다. 파드는 이 범위에서 IP를 할당받습니다.
serviceSubnet: 10.200.1.0/24 #서비스 IP를 위한 CIDR 범위를 정의합니다. 서비스는 이 범위에서 IP를 할당받습니다.
MetalLB
Load Balancer Type은 클라우드 벤더의 로드밸런서만 지원한다. 그렇기에 OnPremise 환경에서는 적용할 수 없는데, MetalLB는 bare metal 전용 로드밸런서를 제공한다.
MetallLB는 ARP, BPG 2가지 모드를 지원한다.
ARP(L2)
서비스가 생성되면 Hash 알고리즘을 통해 Leader 노드를 선정한다. 선정된 노드에 존재하는 Speaker 파드가 해당 LB의 외부 IP를 ARP로 광고한다. 덕분에 클라이언트가 LB로 접근하면 클라이언트는 해당 노드로 들오게 된다. 이후로는 서비스의 Iptables 룰에 의해 각 엔드포인트 파드로 라우팅된다.
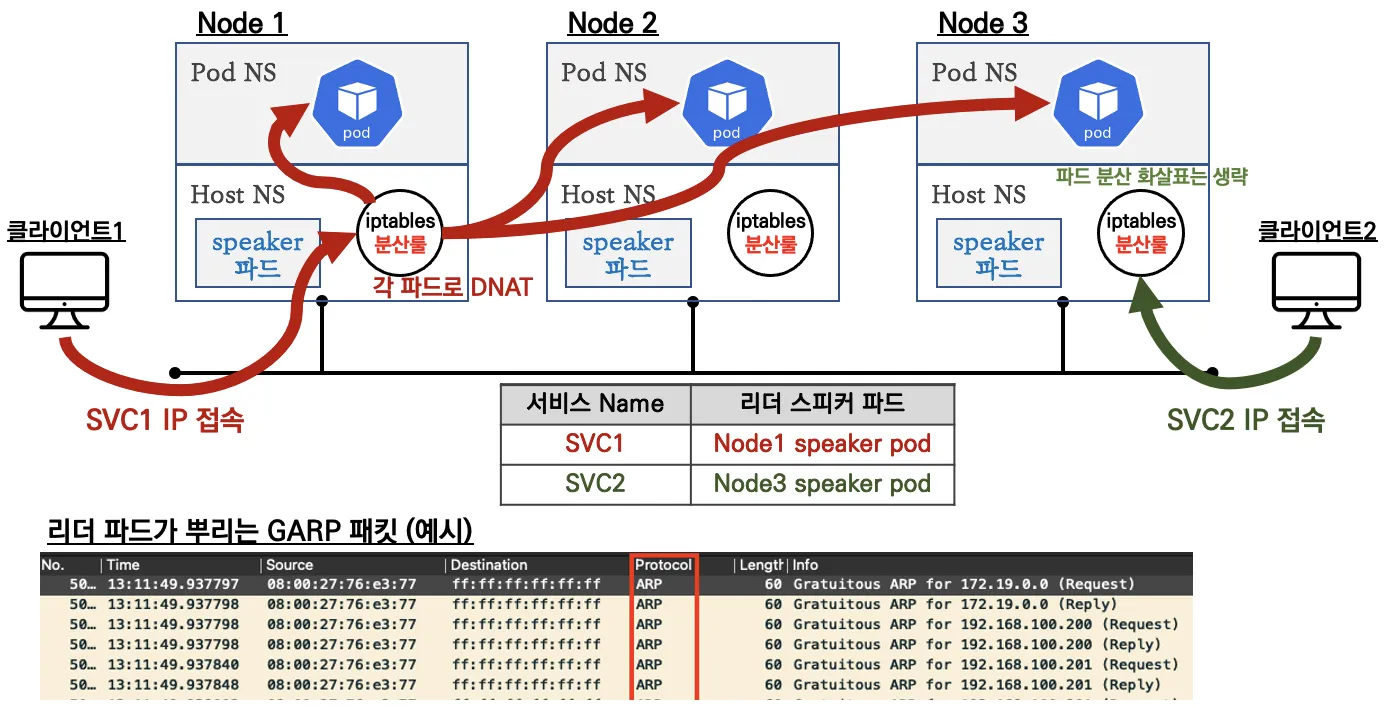
해당 모드는 Failover가 가능하지만, 트래픽 분산이 어렵다. 특정 노드로 유입된 후 다시 분산되기에 네트워크 홉이 비효율적이다. 또한, 하지만 리더 장애시 Failover되는데 1분정도 걸린다고 하여 운영환경에서 사용하기엔 무리가 있다.
실습
배포
MetalLB YAML 파일을 배포한다.
1
kubectl apply -f https://raw.githubusercontent.com/metallb/metallb/v0.14.8/config/manifests/metallb-native.yaml
배포 후 스피커 파드를 확인하면, 네트워크 모드가 Host로 동작하여 노드의 IP와 같은 것을 확인할 수 있다.
1
2
3
4
5
6
7
kubectl get pod -n metallb-system -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
controller-8694df9d9b-5ljkq 1/1 Running 0 33s 10.10.1.2 myk8s-worker3 <none> <none>
speaker-558tq 1/1 Running 0 31s 172.18.0.5 myk8s-control-plane <none> <none>
speaker-mmckd 1/1 Running 0 32s 172.18.0.3 myk8s-worker <none> <none>
speaker-pcjs2 1/1 Running 0 32s 172.18.0.2 myk8s-worker3 <none> <none>
speaker-xlbzv 1/1 Running 0 31s 172.18.0.4 myk8s-worker2 <none> <none>
docker의 IP 대역을 확인한다.

ExternalIP Pool을 설정한다. kind와 같은 ip 대역으로 설정하여 트래픽이 클러스터로 유입되도록 한다.
1
2
3
4
5
6
7
8
9
10
cat <<EOF | kubectl apply -f -
apiVersion: metallb.io/v1beta1
kind: IPAddressPool
metadata:
name: my-ippool
namespace: metallb-system
spec:
addresses:
- 172.18.255.200-172.18.255.250
EOF
L2Advertisement 생성한다. 위에서 확인한 Docker IP 대역을 기반으로 L2 모드로 LoadBalancer IP를 사용한다.
1
2
3
4
5
6
7
8
9
10
cat <<EOF | kubectl apply -f -
apiVersion: metallb.io/v1beta1
kind: L2Advertisement
metadata:
name: my-l2-advertise
namespace: metallb-system
spec:
ipAddressPools:
- my-ippool
EOF
파드와 서비스를 배포한다
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
cat <<EOF | kubectl apply -f -
apiVersion: v1
kind: Pod
metadata:
name: webpod1
labels:
app: webpod
spec:
nodeName: myk8s-worker
containers:
- name: container
image: traefik/whoami
terminationGracePeriodSeconds: 0
---
apiVersion: v1
kind: Pod
metadata:
name: webpod2
labels:
app: webpod
spec:
nodeName: myk8s-worker2
containers:
- name: container
image: traefik/whoami
terminationGracePeriodSeconds: 0
EOF
서비스 배포
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
cat <<EOF | kubectl apply -f -
apiVersion: v1
kind: Service
metadata:
name: svc1
spec:
ports:
- name: svc1-webport
port: 80
targetPort: 80
selector:
app: webpod
type: LoadBalancer # 서비스 타입이 LoadBalancer
---
apiVersion: v1
kind: Service
metadata:
name: svc2
spec:
ports:
- name: svc2-webport
port: 80
targetPort: 80
selector:
app: webpod
type: LoadBalancer
---
apiVersion: v1
kind: Service
metadata:
name: svc3
spec:
ports:
- name: svc3-webport
port: 80
targetPort: 80
selector:
app: webpod
type: LoadBalancer
EOF
service/svc1 created
service/svc2 created
service/svc3 created
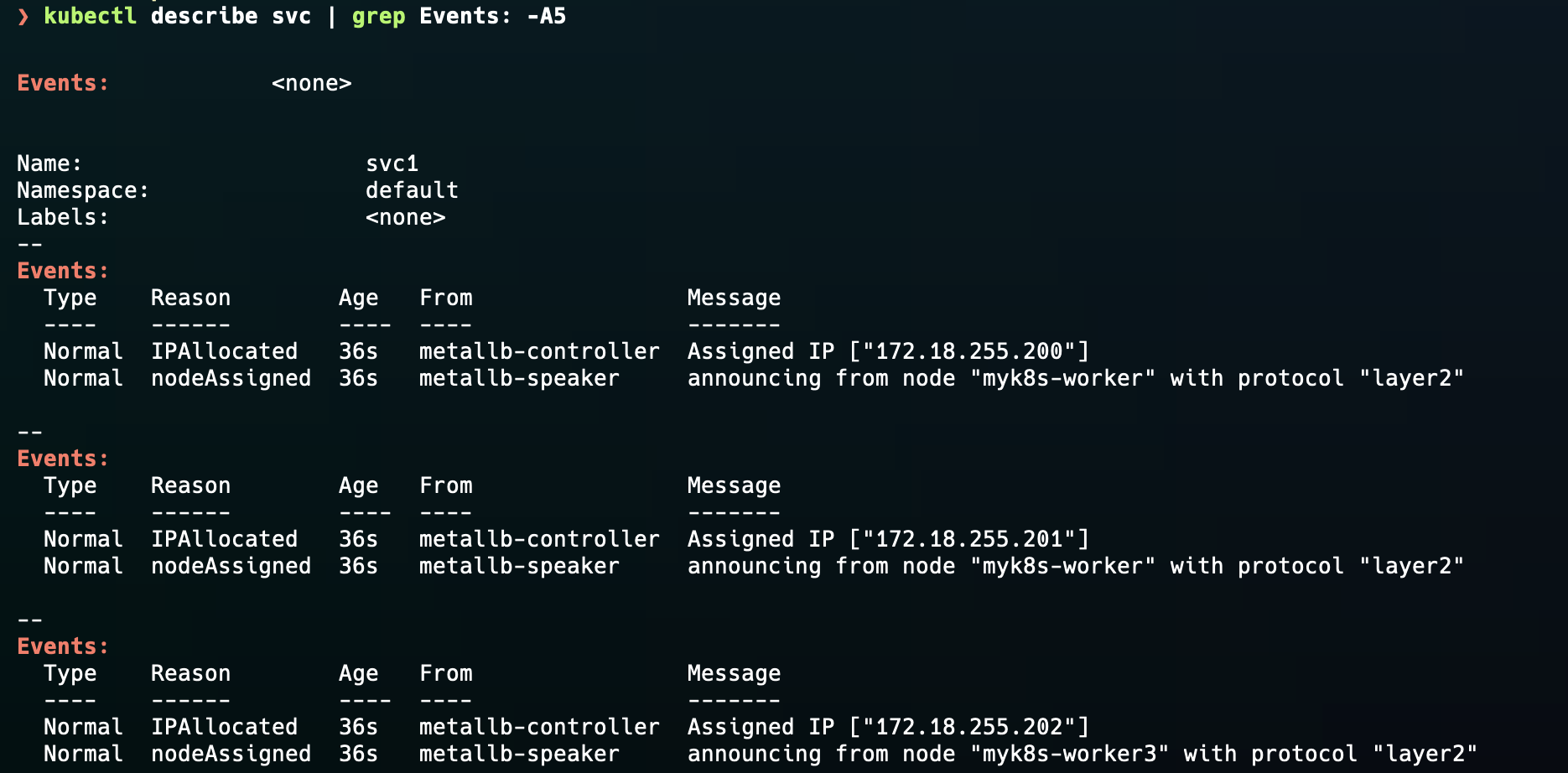
서비스가 정상적으로 생성된 것을 확인할 수 있고, describe 해보면 리더가 어디에 할당되었는지 알 수 있다.
*서비스를 삭제 및 재배포해도, IP를 통해 해시값으로 리더를 선출하기에 리더는 동일하다. (아래의 코드 설명 참고)
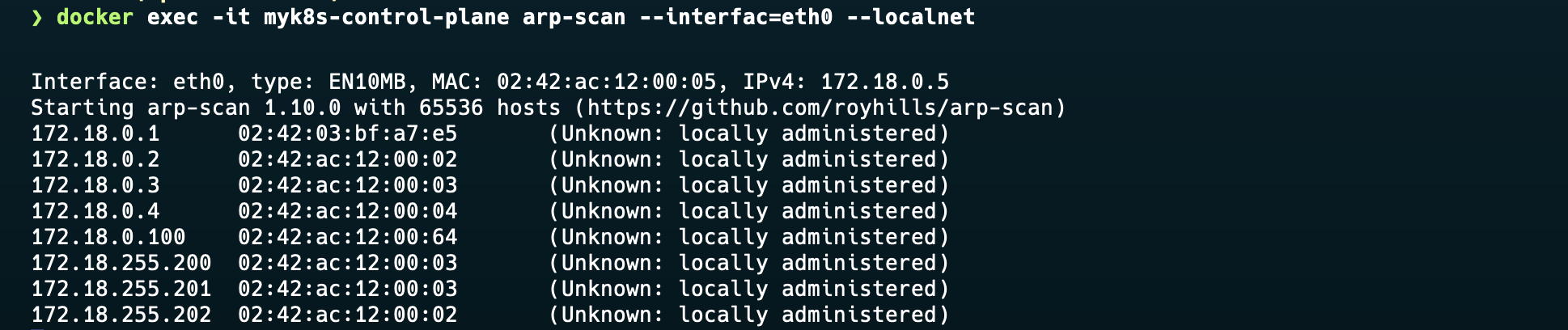
이제 controlplane에서 ARP-Scan을 활성화하여, ARP로 ExternalIP를 광고하는 것을 확인한다. 아래의 사진처럼 172.18.255.200 ~ 202까지 서비스의 ExternalIP를 확인할 수 있다.
부하분산 확인
이제 mypc 컨테이너에 접근하여 부하 분산을 확인해본다.
1
2
3
4
docker exec -it mypc zsh -c "for i in {1..100}; do curl -s $SVC1EXIP | grep Hostname; done | sort | uniq -c | sort -nr"
51 Hostname: webpod1
49 Hostname: webpod2
1
2
3
4
docker exec -it mypc zsh -c "for i in {1..100}; do curl -s $SVC2EXIP | grep Hostname; done | sort | uniq -c | sort -nr"
55 Hostname: webpod1
45 Hostname: webpod2
iptables Rule
Iptables의 규칙 또한 NodePort와 거의 동일하다고 한다.
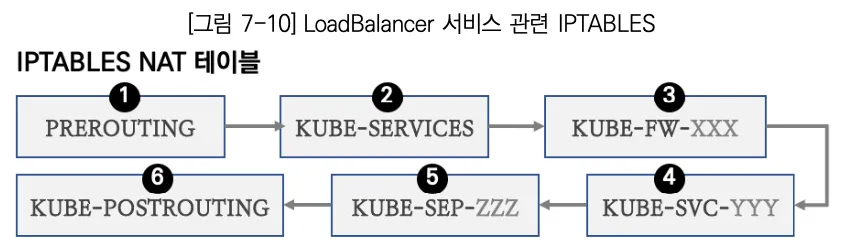
리더 파드로 선출된 노드에 접근하여, iptables 규칙을 확인한다. 아래와 같이 ExternalIP에 대해서 KUBE-EXT > KUBE-SVC 로 라우팅되는 것을 확인할 수 있다.
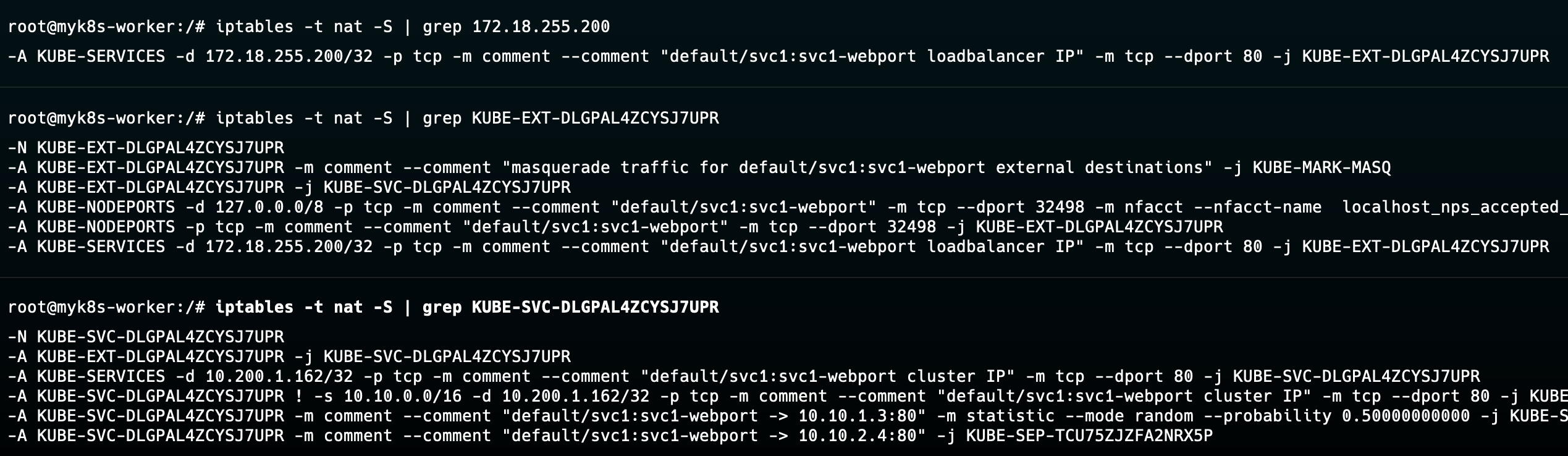
장애 재현
이제 리더 노드에 장애를 재현하여 Failover를 확인해본다.
1
2
docker stop myk8s-worker --signal 9
myk8s-worker
myk8s-worker 노드가 죽은 것을 확인한다.
1
2
3
4
5
6
docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
c08665282fca kindest/node:v1.31.0 "/usr/local/bin/entr…" About an hour ago Up About an hour myk8s-worker3
21a0814fe11b kindest/node:v1.31.0 "/usr/local/bin/entr…" About an hour ago Up About an hour myk8s-worker2
637f93f4b5d1 kindest/node:v1.31.0 "/usr/local/bin/entr…" About an hour ago Up About an hour 0.0.0.0:30000-30004->30000-30004/tcp, 127.0.0.1:54294->6443/tcp myk8s-control-plane
7f63f1e8a000 nicolaka/netshoot "sleep infinity" 2 hours ago Up 2 hours mypc
아래와 같이 “speakerlist.go”에서 장애가 발생한 워커노드 IP 대역에 대한 에러로그가 나온다.

조금 기다린 후 svc에 대한 이벤트를 확인해보면, 아래와 같이 새로운 리더가 선출된 것을 확인할 수 있다.
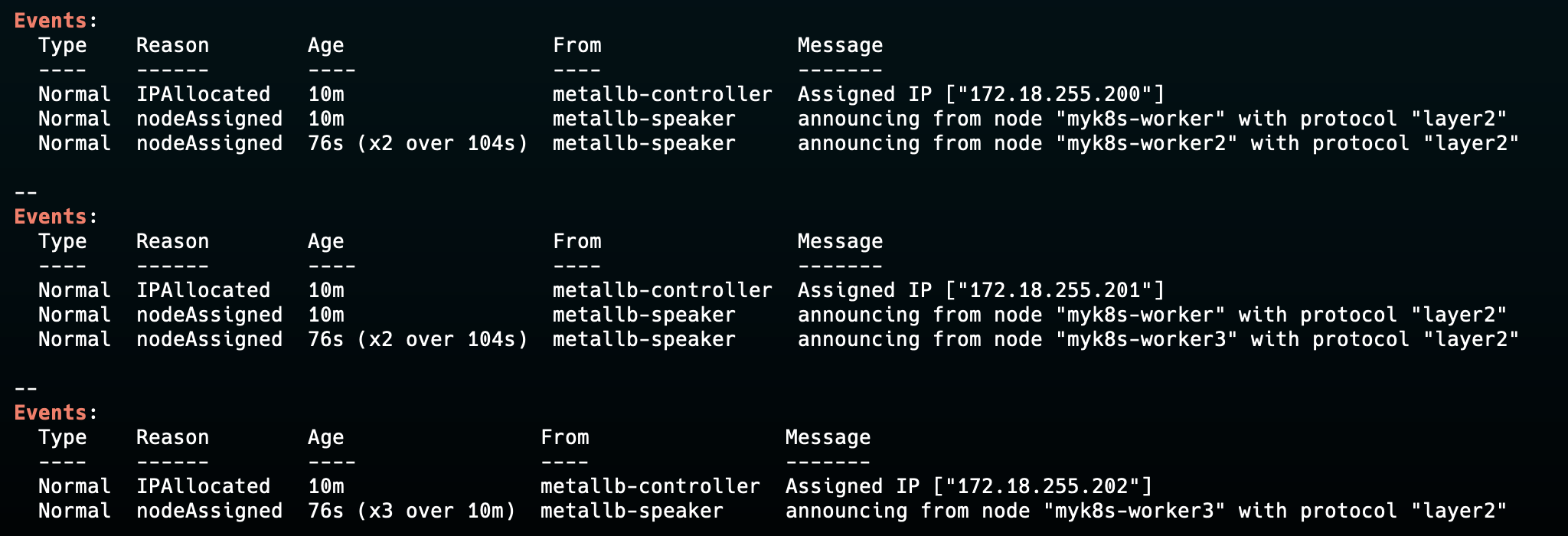
이제 접속을 진행해보면, worker 노드에 있는 pod1도 같이 죽어 pod2로만 접근되는 것을 확인할 수 있다.
1
2
3
4
k get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
webpod1 1/1 Running 0 69m 10.10.2.4 myk8s-worker <none> <none>
webpod2 1/1 Running 0 69m 10.10.1.3 myk8s-worker2 <none> <none>
1
2
docker exec -it mypc zsh -c "for i in {1..100}; do curl -s $SVC1EXIP | grep Hostname; done | sort | uniq -c | sort -nr"
100 Hostname: webpod2
BGP
BPG 모드는 외부 라우터와 연동하여 동작한다. speaker 파드는 BGP 프로토콜을 통해 ExternalIP를 라우터에게 전파한다. 외부 라우터와 연동되기에 externalTrafficPolicy: Local로 설정하여 들어온 노드에 파드로 라우팅한다. 이를 통해 노드로 트래픽이 들어오고 다시 분산되는 불필요한 과정을 없앨 수 있다.
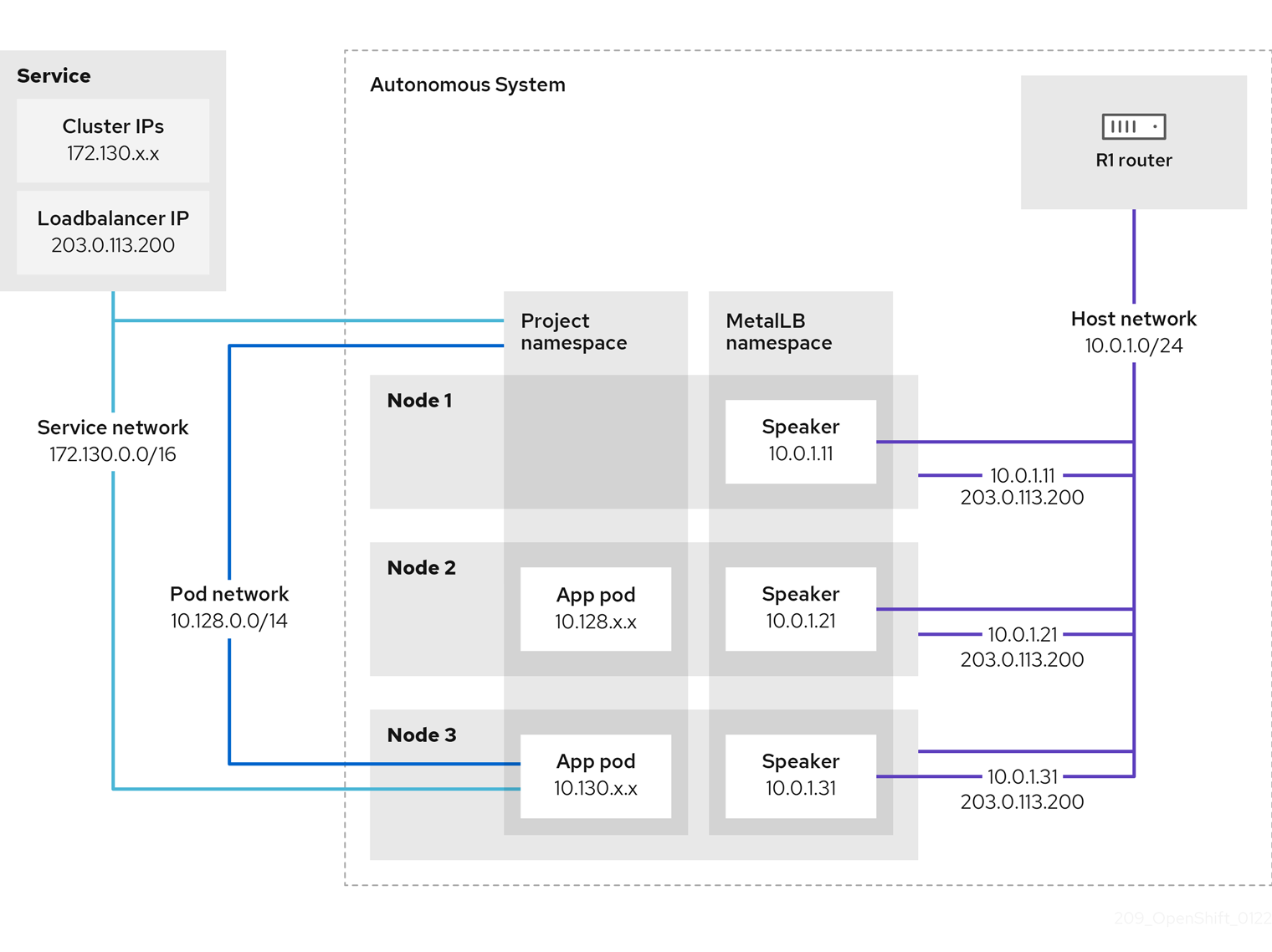
또한, externalTrafficPolicy: Local 로 설정되는 경우 파드가 노드에 골고루 분산된게 아닌 특정 노드에 몰려있다면 부하가 발생한다. 그렇기에 pod anti-affinity과 같은 옵션으로 파드를 골고루 분산을 권장한다고 한다.
*BGP는 외부 라우터와 연동되어야 하므로 실습은 다루지 않습니다.
metalLB 코드 살펴보기
speaker/main.go 코드를 살펴보면
handleService에서 VIP(ExternalIP)에 대한 광고를 진행한다.
- 해당 서비스가 외부 IP를 가진 LB 타입의 서비스이고, 외부 IP가 MetalLB IP pool에 속하는지 확인한다.(func
SetBalancer) - 해당 노드가 리더인지 확인한다. (
func ShouldAnnounce)
맞다면 ExternalIP에 대한 광고를 진행한다.
리더 선출(Layer2)
layer2_controller.go 코드를 확인해보면, usablesNode 함수에서 가용한 노드를 파악한다. ShouldAnnounce 함수에서 서비스 별로 노드를 선정하는데, NodeName + “#” + externalIP 에 대한 해시값으로 선정한다.
이 방식 덕분에 노드가 추가되어도, 해당 노드에 대한 해시값이 가장 먼저오는 경우가 아니라면 리더는 그대로 유지된다. 해시 덕분에 어떤 노드가 리더로 선정되었는지 기억하지 않아도 stateless하게 작업을 진행할 수 있다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
...
// Using the first IP should work for both single and dual stack.
ipString := toAnnounce[0].String()
// Sort the slice by the hash of node + load balancer ips. This
// produces an ordering of ready nodes that is unique to all the services
// with the same ip.
sort.Slice(availableNodes, func(i, j int) bool {
hi := sha256.Sum256([]byte(availableNodes[i] + "#" + ipString))
hj := sha256.Sum256([]byte(availableNodes[j] + "#" + ipString))
return bytes.Compare(hi[:], hj[:]) < 0
})
// Are we first in the list? If so, we win and should announce.
if len(availableNodes) > 0 && availableNodes[0] == c.myNode {
return ""
}
// Either not eligible, or lost the election entirely.
return "notOwner"