TCP Kernel 코드 살펴보기
TCP Kernel 코드 살펴보기
들어가며
TCP/IP 관련 이론을 정리하다가 내가 배운 이론과 실제 동작 방식이 어떻게 다른지 궁금해 리눅스 커널에 구현된 TCP 코드를 살펴보기로 했다. 리눅스 커널 코드를 전부 들여다보는 건 무리가 있을 것 같아 실제 TCP 연결 과정과 송신, 수신을 위주로 정리했다.
미리보기
소스코드를 보면서 새롭게 알게 된 내용이 많았는데, 우선 간단하게 정리해 보면 다음과 같다.
TCP Fast Open(TFO)
TFO는 TCP 확장 프로토콜로, 한번 연결했던 대상과 다시 연결할 때 TFO 쿠키를 사용하여 핸드셰이크와 데이터 전송을 같이할 수 있다. 덕분에 2-RTT에서 1-RTT로 성능개선이 가능하다.
과거에 연결했던 대상에게서 TFO 쿠키를 획득하고 이후 과정에서 쿠키를 통해 인증받을 수 있다. 클라이언트는 다음 연결 시 SYN 패킷에 쿠키와 데이터를 포함하여 전송한다. 서버는 쿠키를 확인하여 신원을 검사하고 정상적으로 인증된 경우 데이터 패킷을 받고 Fast Open을 진행한다.
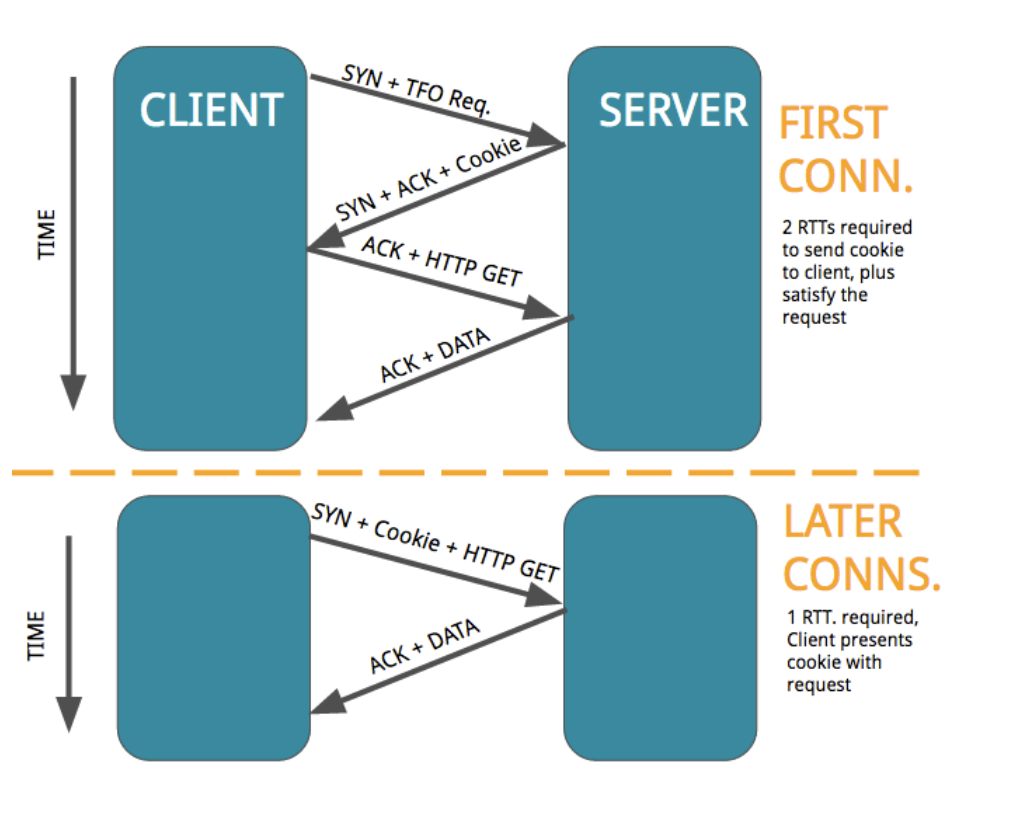
출처: https://reproducingnetworkresearch.wordpress.com/2016/05/30/cs244-16-tcp-fast-open/
SYN Flooding
SYN Flooding이란 비정상적으로 대량의 SYN 패킷을 특정 서버로 보내 공격하는 방법이다. 대량의 SYN 패킷이 들어오면 서버는 연결을 위해 포트를 열고 기다린다. 하지만, 비정상적인 IP이므로 응답은 없고 지속적으로 새로운 SYN 패킷을 받다 포트가 고갈되어 문제가 발생한다.
이를 커널 파라미터(sysctl.sysctl_tcp_syncookies) 설정으로 SYN flooding 방어를 설정할 수 있다. 커널 파라미터로 설정할 경우 SYN 패킷이 왔을 때 쿠키를 보내고 연결을 닫아둔다. 해당 쿠키를 갖고 다시 시도하는 대상에게만 연결을 시도한다.
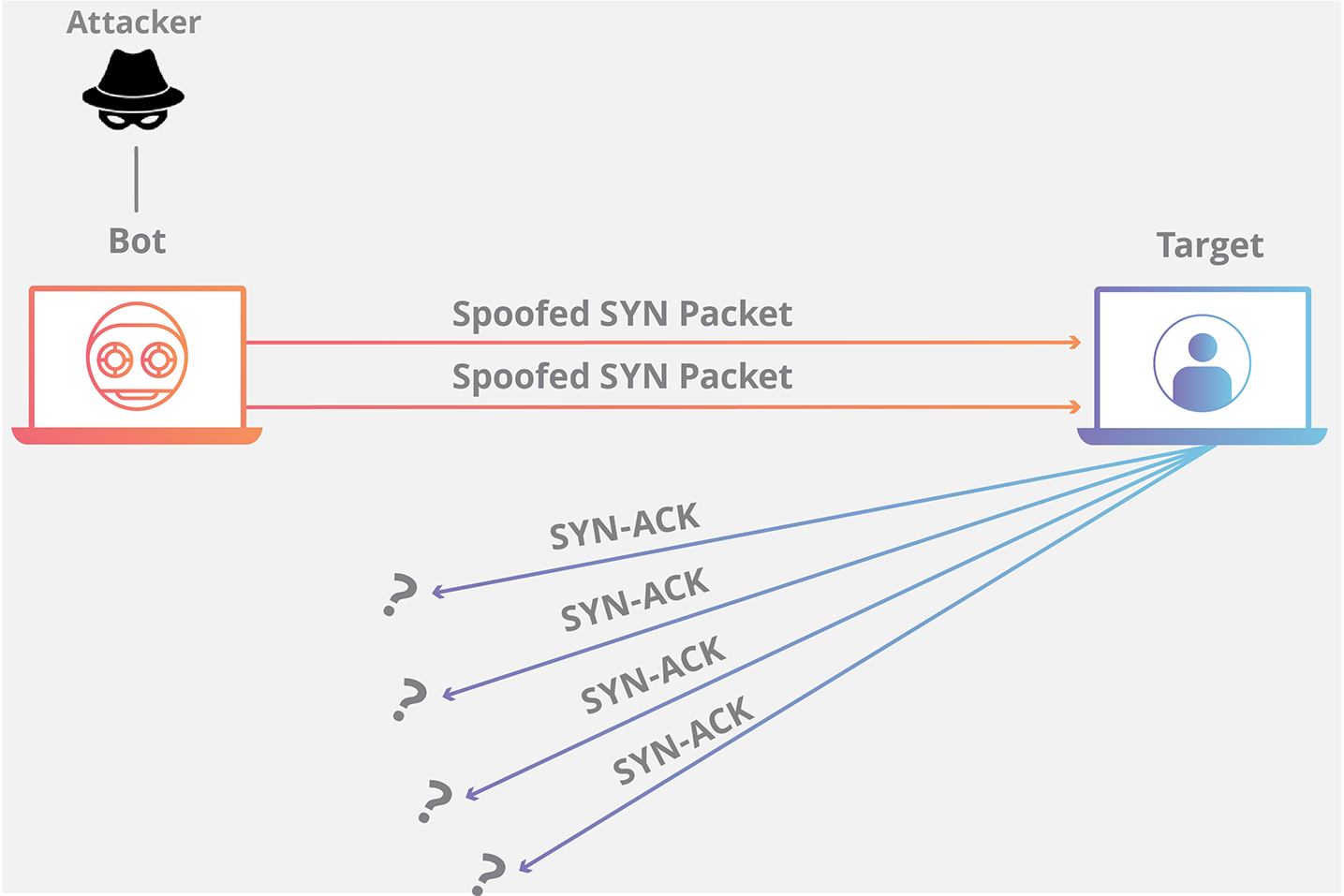
출처: https://www.cloudflare.com/ko-kr/learning/ddos/syn-flood-ddos-attack/
TCP Security
TCP에서 별도로 인증 기능이 있다. 암호화/복호화가 아닌 해당 패킷이 유효함을 인증한다. 헤더의 옵션 필드를 통해 진행하며, 인증 과정에서 별도의 키를 공유하고 키를 기반으로 각 패킷을 인증할 수 있다.
TCP AO(TCP Authentication Option)는 TCP 연결에 대한 인증을 제공하는 옵션으로, 기존의 TCP MD5 서명 옵션(RFC 2385)을 대체하는 방식이라고 한다.
PAWS(Protection Against Wrapped Sequence Numbers)
TCP 옵션으로 타임스탬프가 존재하며, 시간을 가지고 부적절한 패킷을 구별할 수 있다. 수신된 패킷의 전송 시간과 내가 가장 최근에 받은 패킷의 수신 시간을 비교하여, 전송 시점이 최근 패킷 수신 시점보다 과거라면 패킷을 버린다. 덕분에 순서번호 래핑문제(MAX에서 0으로 순회하면서 발생할 수 있는 문제)와 같은 패킷을 중복으로 받는 문제를 사전에 방지할 수 있다.
fastpath, slowpath
리눅스에서는 패킷 수신 시 fastpath와 slowpath, 두 가지 경우로 나눈다.
아래의 조건을 만족하면 fastpath로 진행하고, 별다른 검사 없이 패킷을 수신하여 처리 속도를 높인다. slowpath의 경우 패킷을 꼼꼼히 검사한 뒤 정상이면 수신한다.
- TCP 플래그가 예상값과 일치(
ACK or PSH + ACK) - 수신한 패킷 순서 번호가 예상값과 일치(
패킷 순서번호 == rcv_nxt) - ACK 번호가 송신할 다음 시퀀스번호 보다 작은지(
snd_nxt > ack)
htonl
htonl은 translate address host to network long의 약자로 호스트 순서번호를 네트워크 바이트 순서로 변환한다. 실제 컴퓨터마다 리틀 엔디안, 빅엔디안 등 방식이 다르기에 이를 통일하는 역할을 수행한다. 네트워크는 빅엔디안을 표준으로 삼는다.
SACK (Selective ACK)
실제 리눅스에서는 슬라이드 윈도우 관리 방법으로 SACK를 사용한다. 이는 Go-back-n과 다르게 못받은 패킷만 재전송한다.
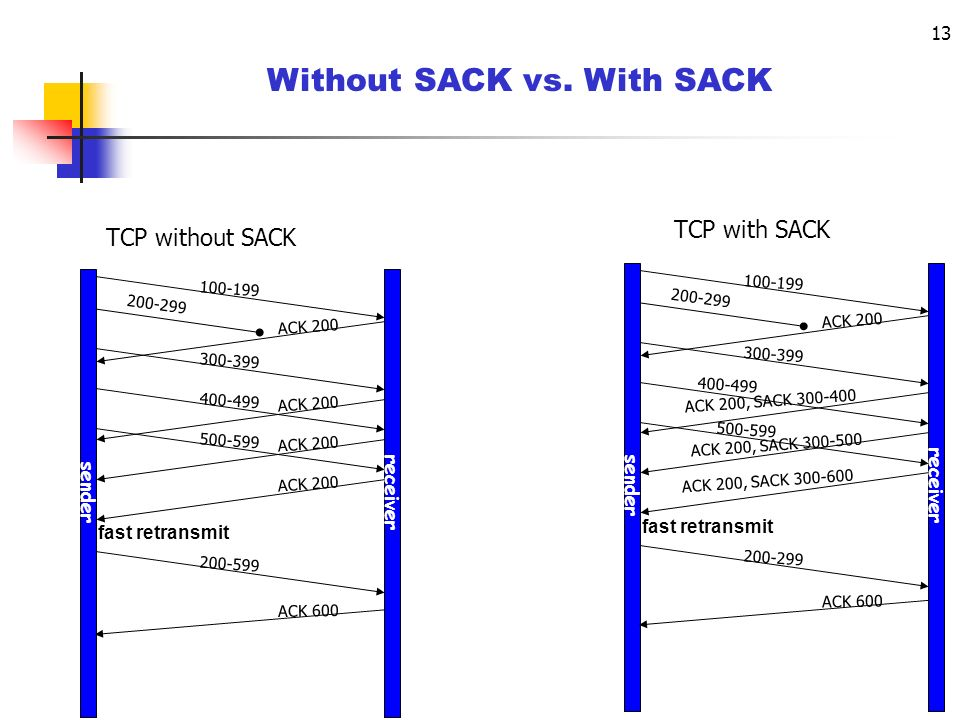
출처: https://slideplayer.com/slide/7916092/
실제 코드
이제 실제 코드를 살펴보면서 TCP 연결과정 및 송신 수신과정을 살펴보자. TCP 구조체의 주요 변수를 살펴보고, 핸드셰이크, 송신 및 수신과정을 순서대로 살펴볼 예정이다.
구조체
TCP Header
TCP Header 종류는 자주 봤을 법한 SYN, ACK, FIN을 비롯해 8개로 구성된다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
//종료
#define TCPHDR_FIN 0x01
//연결 시작
#define TCPHDR_SYN 0x02
//리셋
#define TCPHDR_RST 0x04
//데이터를 즉시 상위 계층으로 전달
#define TCPHDR_PSH 0x08
//응답
#define TCPHDR_ACK 0x10
//긴급 데이터 포함 유무
#define TCPHDR_URG 0x20
//ECN(Echo Congestion Notification), 수신 측이 혼잡 상태 알림
#define TCPHDR_ECE 0x40
//Congestion Window Reduced, 송신자가 윈도우 축소 알림
#define TCPHDR_CWR 0x80
TCP Socket
아래에서 TCP 통신에서 사용하는 슬라이드 윈도우 관련 변수와 네트워크 상태 파악 및 혼란 제어에 사용되는 변수를 확인할 수 있었다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
struct tcp_sock {
...
u32 max_window; /* Maximal window ever seen from peer */
u32 rcv_ssthresh; /* Current window clamp */
...
// ======================== 송신 관련 ========================
u32 copied_seq; // 아직 전달되지 않은 데이터 순서 번호
u32 snd_ssthresh; // slow start 임계치
u32 write_seq; // 전송할 데이터의 마지막 바이트 +1을 가리키는 포인터 (전송 이후 다음에 보낼 데이터 위치)
u32 snd_nxt; // 전송할 데이터 위치
// ======================== 수신 관련 ========================
u32 snd_una; // 현재 받은 ACK 번호
u32 rcv_nxt; // 다음에 수신할 번호
u32 rcv_wnd; // 수신 관련 윈도우 사이즈
// ======================== 네트워크 상태 및 혼란 제어 ========================
// RTT의 변동값을 기록하여 혼잡 제어 및 재전송 타이머에 사용
u32 srtt_us; /* smoothed round trip time << 3 in usecs */
u32 rttvar_us; /* smoothed mdev_max */
// 혼잡 제어 관련
struct hrtimer pacing_timer; // 전송 간격 조절을 위한 타이머
struct hrtimer compressed_ack_timer;
// RTO, Retransmission Timeout의 약자로,
// 전송한 데이터에 대해 ACK를 기다리는 시간으로,RTO가 지나면 보낸 데이터를 유실로 판단하고 재전송한다.
u16 total_rto; //
u16 total_rto_recoveries; // Total number of RTO recoveries,
u32 total_rto_time; /* ms spent in (completed) RTO recoveries. */
...
};
TCP State
아래 코드를 보면 TCP Socket State를 기반으로 처리하기에 아래의 state flow를 같이 정리했다.
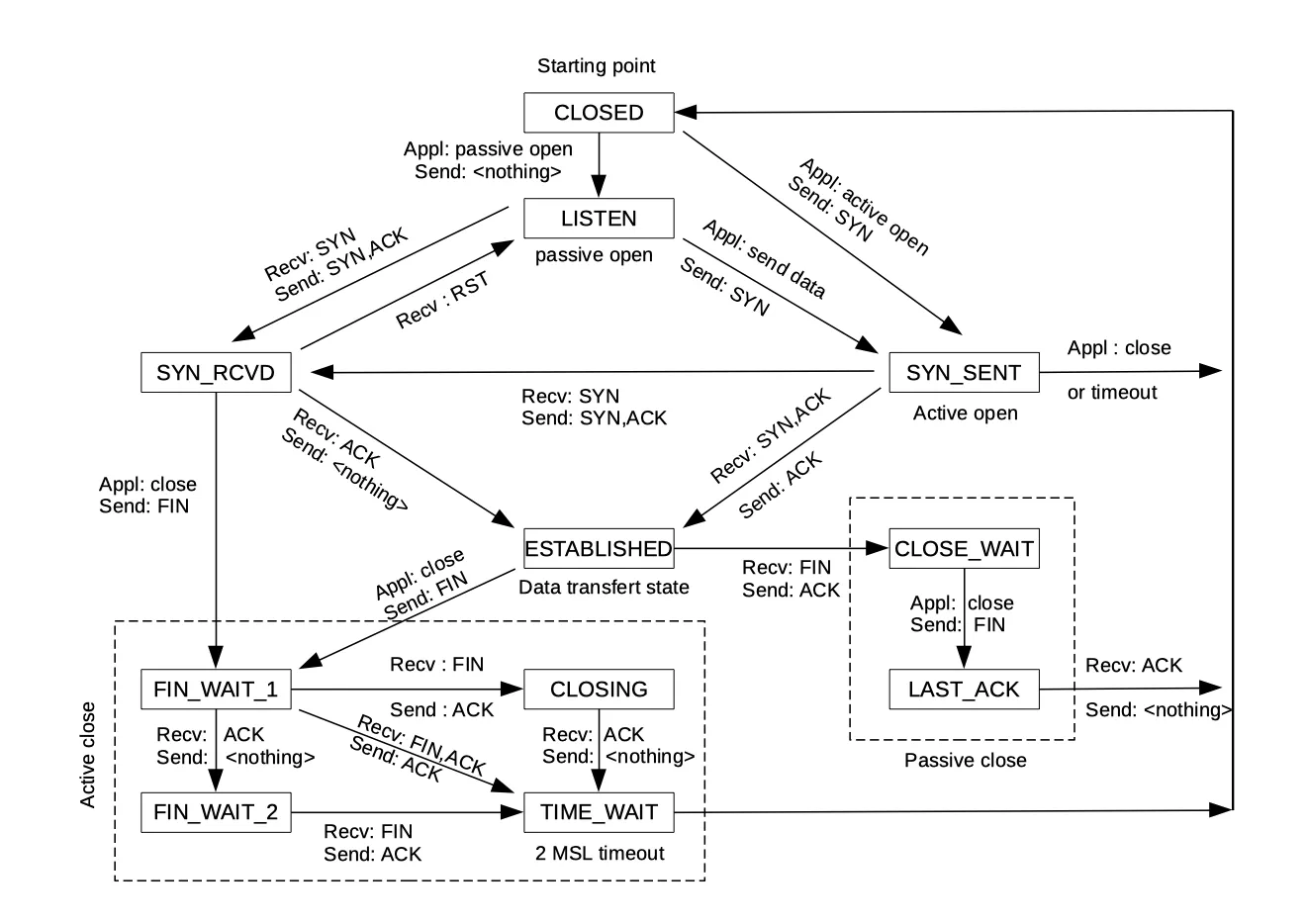
출처: https://www.ibm.com/support/pages/flowchart-tcp-connections-and-their-definition
추가로 소스코드를 살펴보다보면 mss라는 용어가 자주나온다. mss는 Maximum Segment Size의 약자로, TCP 연결에서 한 번에 전송할 수 있는 데이터의 최대 크기, 즉 TCP 헤더를 제외한 데이터의 최대 크기를 의미하며 MTU(Maximum Transmission Unit)값을 고려하여 결정한다.
핸드셰이크
이제 본격적으로 핸드셰이크 과정을 살펴보자. TCP는 3-way 핸드셰이크를 진행한다. SYN > SYN + ACK > ACK 으로 진행되는데, 순서대로 이를 살펴본다.
SYN(TCP_LISTEN > TCP_SYN_SENT)
코드의 흐름을 살펴보면, 아래의 과정으로 진행된다.
소켓 할당 및 초기화 > header 데이터(SYN 설정) > fastopen or 일반방식으로 SYN 패킷 전송
이 과정에서 소켓 상태를 TCP_LISTEN에서 TCP_SYN_SENT 으로 업데이트한다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
int tcp_connect(struct sock *sk)
{
struct tcp_sock *tp = tcp_sk(sk);
struct sk_buff *buff;
int err;
// bpf 관련 코드
tcp_call_bpf(sk, BPF_SOCK_OPS_TCP_CONNECT_CB, 0, NULL);
// TCP는 별도로 TCP-AO이라는 인증 옵션을 진행함
#if defined(CONFIG_TCP_MD5SIG) && defined(CONFIG_TCP_AO)
...
// 소켓 초기화(목적지의 MTU에 맞게 MSS 설정, 슬라이드 윈도우 사이즈 설정, 소켓 구조체 초기화)
tcp_connect_init(sk);
// 소켓 버퍼 할당 받기
buff = tcp_stream_alloc_skb(sk, sk->sk_allocation, true);
if (unlikely(!buff))
return -ENOBUFS;
// 패킷 초기화 및 Header 데이터
tcp_init_nondata_skb(buff, tp->write_seq, TCPHDR_SYN);
tcp_mstamp_refresh(tp);
tp->retrans_stamp = tcp_time_stamp_ts(tp);
tcp_connect_queue_skb(sk, buff);
tcp_ecn_send_syn(sk, buff);
// 전송 큐 삽입
tcp_rbtree_insert(&sk->tcp_rtx_queue, buff);
/* Send off SYN; include data in Fast Open. */
// TCP Fast Open을 사용하는 경우, tcp_send_syn_data 함수를 통해 SYN + 데이터 패킷을 보냄
// Fast Open이란 과거에 한번 연결되었던 프로그램으로,
// TFO 쿠키를 통해 3-way handshake를 생략하고 바로 데이터를 전송하는 방식
// 아래에서 데이터 전송이 일어남
err = tp->fastopen_req ? tcp_send_syn_data(sk, buff) :
tcp_transmit_skb(sk, buff, 1, sk->sk_allocation);
if (err == -ECONNREFUSED)
return err;
/* We change tp->snd_nxt after the tcp_transmit_skb() call
* in order to make this packet get counted in tcpOutSegs.
*/
WRITE_ONCE(tp->snd_nxt, tp->write_seq);
tp->pushed_seq = tp->write_seq;
// buffer & slide windows update
buff = tcp_send_head(sk);
if (unlikely(buff)) {
// snd_nxt update
WRITE_ONCE(tp->snd_nxt, TCP_SKB_CB(buff)->seq);
tp->pushed_seq = TCP_SKB_CB(buff)->seq;
}
/* Timer for repeating the SYN until an answer. */
// 재전송 타이머
inet_csk_reset_xmit_timer(sk, ICSK_TIME_RETRANS,
inet_csk(sk)->icsk_rto, TCP_RTO_MAX);
return 0;
}
SYN + ACK(TCP_LISTEN > TCP_SYN_RECV)
TCP_LISTEN 소켓 상태로 패킷을 수신하면 tcp_rcv_state_process 함수가 호출된다. 해당 함수에서 TCP_LISTEN 상태라면 tcp_conn_request 함수를 호출하여 소켓을 초기화하고 send_synack 함수를 통해 SYN+ACK를 송신한다. 이후 소켓 상태를 TCP_SYN_RECV으로 업데이트 한다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
enum skb_drop_reason tcp_rcv_state_process(struct sock *sk, struct sk_buff *skb)
{
...
case TCP_LISTEN:
...
if (th->syn) {
...
/* It is possible that we process SYN packets from backlog,
* so we need to make sure to disable BH and RCU right there.
*/
rcu_read_lock();
local_bh_disable();
icsk->icsk_af_ops->conn_request(sk, skb);
local_bh_enable();
rcu_read_unlock();
consume_skb(skb);
return 0;
}
SKB_DR_SET(reason, TCP_FLAGS);
goto discard;
...
}
호출된 tcp_conn_request 함수에서 syn+ack 동작을 수행한다. 여기서 위의 미리보기에서 언급한 SYN Flooding을 방어하는 쿠키 설정이 커널에 되어있다면 SYN 쿠키를 사용한다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
int tcp_conn_request(struct request_sock_ops *rsk_ops,
const struct tcp_request_sock_ops *af_ops,
struct sock *sk, struct sk_buff *skb)
{
...
// kernel tcp syn 쿠키 설정을 확인한다.(flooding 공격 방지 설정)
// 0: 사용안함,
// 1: 시스템이 SYN 플러드 공격을 감지할 때만 SYN 쿠키 사용
// 2: 항상 SYN 쿠키 사용
syncookies = READ_ONCE(net->ipv4.sysctl_tcp_syncookies);
// syncookies가 2이거나, SYN 요청을 받는 큐가 가득 찼을 때
if (syncookies == 2 || inet_csk_reqsk_queue_is_full(sk)) {
// tcp_syn_flood_action 함수는 "Return true if a syncookie should be sent"
want_cookie = tcp_syn_flood_action(sk,rsk_ops->slab_name);
...
}
}
...
// 연결을 위한 임시 소켓 생성
req = inet_reqsk_alloc(rsk_ops, sk, !want_cookie);
req->syncookie = want_cookie;
tcp_rsk(req)->af_specific = af_ops;
tcp_rsk(req)->ts_off = 0;
tcp_rsk(req)->req_usec_ts = false;
...
// 전송 진행
if (fastopen_sk)
// fastopen 케이스로 SYN과 함께 온 데이터를 저장하고, synack 전송
af_ops->send_synack(fastopen_sk, dst, &fl, req,
&foc, TCP_SYNACK_FASTOPEN, skb);
// req = request 소켓으로 송신자로부터 들어온 데이터를 가지고 있다.
// 이를 아래처럼 inet_csk_reqsk_queue_add으로 accept queue에 추가한다.
if (!inet_csk_reqsk_queue_add(sk, req, fastopen_sk)) {
reqsk_fastopen_remove(fastopen_sk, req, false);
bh_unlock_sock(fastopen_sk);
sock_put(fastopen_sk);
goto drop_and_free;
}
sk->sk_data_ready(sk);
bh_unlock_sock(fastopen_sk);
sock_put(fastopen_sk);
} else {
// 일반 케이스
tcp_rsk(req)->tfo_listener = false;
...
// synack 전송
af_ops->send_synack(sk, dst, &fl, req, &foc,!want_cookie ? TCP_SYNACK_NORMAL :
TCP_SYNACK_COOKIE,skb);
if (want_cookie) {
reqsk_free(req);
return 0;
}
}
...
}
ACK(TCP_SYN_SENT > TCP_ESTABLISHED)
tcp_rcv_synsent_state_process 함수에서 진행하며, ACK와 PAWS를 통해 패킷의 유효성을 검증한다. 이후 ACK 처리를 진행하고 소켓 상태를 TCP_SYN_SENT에서 TCP_ESTABLISHED으로 업데이트 한다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
static int tcp_rcv_synsent_state_process(struct sock *sk, struct sk_buff *skb,
const struct tcphdr *th)
{
...
if (th->ack) {
// If SEG.ACK =< ISS(Initial Send Sequence), or SEG.ACK > SND.NXT, send a reset
// ACK 검증(ISS < ack < snd_nxt)인지 확인
if (!after(TCP_SKB_CB(skb)->ack_seq, tp->snd_una) ||
after(TCP_SKB_CB(skb)->ack_seq, tp->snd_nxt)) {
// 범위에 맞지 않으면 타이머 재설정 후 drop
if (icsk->icsk_retransmits == 0)
inet_csk_reset_xmit_timer(sk,
ICSK_TIME_RETRANS,
TCP_TIMEOUT_MIN, TCP_RTO_MAX);
SKB_DR_SET(reason, TCP_INVALID_ACK_SEQUENCE);
goto reset_and_undo;
}
// PAWS 검사 (RFC7323) protection against wrapped sequence numbers
// (가장 최근 수신 시각 <= 패킷 송신 시각 <= 현재 시각) 인지 확인
if (tp->rx_opt.saw_tstamp && tp->rx_opt.rcv_tsecr &&
!between(tp->rx_opt.rcv_tsecr, tp->retrans_stamp,
tcp_time_stamp_ts(tp))) {
NET_INC_STATS(sock_net(sk),
LINUX_MIB_PAWSACTIVEREJECTED);
SKB_DR_SET(reason, TCP_RFC7323_PAWS);
goto reset_and_undo;
}
// Now ACK is acceptable.
// RST 헤더인 경우, SYN인 경우 drop
if (th->rst) {
...
}
if (!th->syn) {
...
}
// 패킷 가공
tcp_ecn_rcv_synack(tp, th);
...
// ack 수신 처리
tcp_ack(sk, skb, FLAG_SLOWPATH);
// mss 동기화
tcp_sync_mss(sk, icsk->icsk_pmtu_cookie);
tcp_initialize_rcv_mss(sk);
// 연결 확립
tcp_finish_connect(sk, skb);
// fastopen 경우 data 수신 및 ack(+data)전송
fastopen_fail = (tp->syn_fastopen || tp->syn_data) &&
tcp_rcv_fastopen_synack(sk, skb, &foc);
if (fastopen_fail)
return -1;
// 일반 경우 ack
tcp_send_ack(sk);
return -1;
}
void tcp_finish_connect(struct sock *sk, struct sk_buff *skb)
{
...
// socket 상태 변경
tcp_set_state(sk, TCP_ESTABLISHED);
// Last 패킷을 받은 시간 초기화
icsk->icsk_ack.lrcvtime = tcp_jiffies32;
...
tp->lsndtime = tcp_jiffies32;
...
}
서버측 ack 수신(TCP_SYN_RECV > TCP_ESTABLISHED)
tcp_rcv_state_process 함수를 통해 ACK를 전달받고 연결을 확립하며 소켓 상태를 TCP_SYN_RECV에서 TCP_ESTABLISHED으로 업데이트한다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
enum skb_drop_reason tcp_rcv_state_process(struct sock *sk, struct sk_buff *skb)
{
...
switch (sk->sk_state) {
case TCP_SYN_RECV:
tp->delivered++; /* SYN-ACK delivery isn't tracked in tcp_ack */
if (!tp->srtt_us)
tcp_synack_rtt_meas(sk, req); // RTT 확인
if (req) {
// FASTOPEN
tcp_rcv_synrecv_state_fastopen(sk);
} else {
// FASTOPEN이 아닌 경우
tcp_try_undo_spurious_syn(sk);
tp->retrans_stamp = 0;
tcp_init_transfer(sk, BPF_SOCK_OPS_PASSIVE_ESTABLISHED_CB,
skb);
WRITE_ONCE(tp->copied_seq, tp->rcv_nxt);
}
tcp_ao_established(sk);
smp_mb();
// 상태 변경
tcp_set_state(sk, TCP_ESTABLISHED);
sk->sk_state_change(sk);
// 초기 설정
tp->snd_una = TCP_SKB_CB(skb)->ack_seq;
tp->snd_wnd = ntohs(th->window) << tp->rx_opt.snd_wscale;
tcp_init_wl(tp, TCP_SKB_CB(skb)->seq);
...
/* Prevent spurious tcp_cwnd_restart() on first data packet */
tp->lsndtime = tcp_jiffies32;
// MSS 초기화
tcp_initialize_rcv_mss(sk);
tcp_fast_path_on(tp);
if (sk->sk_shutdown & SEND_SHUTDOWN)
tcp_shutdown(sk, SEND_SHUTDOWN);
break;
송신(TCP_ESTABLISHED)
이제 핸드셰이크 이후 송신 과정을 살펴보자. 애플리케이션에서 데이터 전송이 필요하면 소켓을 호출한다. 이후 소켓에서 tcp_sendmsg를 호출하며 여러 함수를 통해 데이터는 쪼개져 tcp가 처리할 수 있는 단위가 된다. tcp_transmit_skb에서 TCP 헤더를 구성하고 데이터를 넣으며 이후 IP관련 함수를 호출하여 하위 레이어에 위임한다.
자세한 함수 호출은 아래와 같다.
socket > tcp_sendmsg > tcp_push > tcp_push_pending_frames > tcp_write_xmit > tcp_transmit_skb > IP.. > ....
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
static int __tcp_transmit_skb(struct sock *sk, struct sk_buff *skb,
int clone_it, gfp_t gfp_mask, u32 rcv_nxt)
{
...
inet = inet_sk(sk);
tcb = TCP_SKB_CB(skb);
memset(&opts, 0, sizeof(opts));
...
// header 구성
/* Build TCP header and checksum it. */
th = (struct tcphdr *)skb->data;
th->source = inet->inet_sport;
th->dest = inet->inet_dport;
// htonl은 호스트 순서번호를 네트워크 바이트 순서로 변환함
th->seq = htonl(tcb->seq);
th->ack_seq = htonl(rcv_nxt);
*(((__be16 *)th) + 6) = htons(((tcp_header_size >> 2) << 12) |
tcb->tcp_flags);
th->check = 0;
th->urg_ptr = 0;
...
// 윈도우 크기 설정
skb_shinfo(skb)->gso_type = sk->sk_gso_type;
if (likely(!(tcb->tcp_flags & TCPHDR_SYN))) {
th->window = htons(tcp_select_window(sk));
tcp_ecn_send(sk, skb, th, tcp_header_size);
} else {
/* RFC1323: The window in SYN & SYN/ACK segments
* is never scaled.
*/
th->window = htons(min(tp->rcv_wnd, 65535U));
}
tcp_options_write(th, tp, NULL, &opts, &key);
// icsk->icsk_af_ops->send_check = 체크썸 설정
INDIRECT_CALL_INET(icsk->icsk_af_ops->send_check,
tcp_v6_send_check, tcp_v4_send_check,
sk, skb);
...
// 아래 IP 관련 함수를 호출하여 Segment 전송
err = INDIRECT_CALL_INET(icsk->icsk_af_ops->queue_xmit,
inet6_csk_xmit, ip_queue_xmit,
sk, skb, &inet->cork.fl);
...
return err;
}
수신(TCP_ESTABLISHED)
수신할 때는 패킷을 단순 ACK, 데이터를 포함한 ACK로 구분한다.
단순 ACK의 경우) 슬라이드 윈도우를 포함한 필드값을 업데이트한다.
데이터가 존재하는 경우) 리눅스에서는 fastpath, slowpath 두 가지 방식으로 처리한다.
아래의 조건을 만족하면 fastpath로 진행하여, 별다른 패킷 검사 없이 수신하여 성능을 높인다. slowpath의 경우 패킷을 꼼꼼히 검사한 뒤 정상이면 수신한다.
- TCP 플래그가 예상값과 일치(
ACKorPSH + ACK) - 수신한 패킷 순서 번호가 예상값과 일치(
seq == rcv_nxt) - ACK 번호가 송신할 다음 시퀀스번호 보다 작은지(
snd_nxt)
이후 검증이 완료된 패킷은 헤더를 제거하고 데이터를 수신 큐에 넣는다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
void tcp_rcv_established(struct sock *sk, struct sk_buff *skb)
{
enum skb_drop_reason reason = SKB_DROP_REASON_NOT_SPECIFIED;
const struct tcphdr *th = (const struct tcphdr *)skb->data;
struct tcp_sock *tp = tcp_sk(sk);
unsigned int len = skb->len;
/* TCP congestion window tracking */
trace_tcp_probe(sk, skb);
...
// Fast Path Check vs Slow Path
// - TCP 플래그가 예상값과 일치(ACK or PSH + ACK)
// - 수신한 패킷 순서 번호가 예상값과 일치(패킷 순서번호 == rcv_nxt)
// - ACK 번호가 송신할 다음 시퀀스번호 보다 작은지(snd_nxt)
if ((tcp_flag_word(th) & TCP_HP_BITS) == tp->pred_flags &&
TCP_SKB_CB(skb)->seq == tp->rcv_nxt &&
!after(TCP_SKB_CB(skb)->ack_seq, tp->snd_nxt)) {
int tcp_header_len = tp->tcp_header_len;
...
/* Check timestamp */
...
if (len <= tcp_header_len) {
// 패킷의 헤더만 존재하는 경우 => ACK 패킷 수신시
if (len == tcp_header_len) {
...
tcp_ack(sk, skb, 0);
__kfree_skb(skb);
tcp_data_snd_check(sk);
/* When receiving pure ack in fast path, update
* last ts ecr directly instead of calling
* tcp_rcv_rtt_measure_ts()
*/
tp->rcv_rtt_last_tsecr = tp->rx_opt.rcv_tsecr;
return;
} else { /* Header too small */
...
goto discard;
}
} else {
// 데이터 수신시
int eaten = 0;
bool fragstolen = false;
// checksum 검증
if (tcp_checksum_complete(skb))
goto csum_error;
// RTT 측정
tcp_rcv_rtt_measure_ts(sk, skb);
// 패킷 목적지 캐시 제거
skb_dst_drop(skb);
// TCP header 말고 데이터 부분만 남김
__skb_pull(skb, tcp_header_len);
// 데이터 수신 처리
eaten = tcp_queue_rcv(sk, skb, &fragstolen);
// 데이터 수신 이벤트 발생(상위 계층에 전달용)
tcp_event_data_recv(sk, skb);
if (TCP_SKB_CB(skb)->ack_seq != tp->snd_una) {
// 이미 받은 ACK와 다른 경우 >> 송신 측이 내가 보낸 새로운 데이터를 수신했다는 것
// ack 처리
tcp_ack(sk, skb, FLAG_DATA);
// 송신 상태 점검
tcp_data_snd_check(sk);
// ACK 전송이 이미 스케줄되어 있는지 확인
if (!inet_csk_ack_scheduled(sk))
goto no_ack;
} else {
// 예상 ACK를 재수신한 경우, 수신 슬라이드 윈도우의 snd_wl1만 업데이트
// 최근에 받은 수신 패킷에 대한 정보만 업데이트함
tcp_update_wl(tp, TCP_SKB_CB(skb)->seq);
}
__tcp_ack_snd_check(sk, 0);
}
slow_path: //(tcp_validate_incoming으로 이동하여 패킷을 검증해야함)
if (len < (th->doff << 2) || tcp_checksum_complete(skb))
goto csum_error;
if (!th->ack && !th->rst && !th->syn) {
reason = SKB_DROP_REASON_TCP_FLAGS;
goto discard;
}
/*
* Standard slow path.
*/
// 검증이 완료되면, 아래에서 데이터 수신 처리
if (!tcp_validate_incoming(sk, skb, th, 1))
return;
step5:
reason = tcp_ack(sk, skb, FLAG_SLOWPATH | FLAG_UPDATE_TS_RECENT);
if ((int)reason < 0) {
reason = -reason;
goto discard;
}
tcp_rcv_rtt_measure_ts(sk, skb);
/* Process urgent data. */
tcp_urg(sk, skb, th);
/* step 7: process the segment text */
tcp_data_queue(sk, skb);
tcp_data_snd_check(sk);
tcp_ack_snd_check(sk);
return;
}
혼란 제어
TCP에서 혼잡제어는 크게 4개의 단계로 구분되며, 패킷이 유실된 경우 슬라이드 윈도우 사이즈를 줄인다.
SlowStart
초기 단계로 적합한 윈도우 사이즈를 찾기 위한 단계이다. ACK를 받을 때마다 윈도우 사이즈를 2배씩 증가시킨다. 이 과정은 임계치에 도달할 때까지 진행한다.
Congestion Avoidance(혼란 제어)
SlowStart에서 임계치에 다다르면 진행되는 단계이다. 선형적으로 윈도우 사이즈를 조절한다. 1-RTT마다 윈도우 사이즈를 1mss 정도씩 증가시킨다.
Fast Retransmit(빠른 재전송)
빠른 재전송으로 RTO를 기다리지 않고, 같은 ACK를 3번 이상 받으면 해당 패킷을 유실로 판단하고 해당 패킷을 즉시 재전송한다.
Fast Recovery(빠른 회복)
Fast Retransmit 후 윈도우 사이즈를 초기값(SlowStart 단계)으로 돌아가지 않고, 현재 전송 중인 패킷 수 + 1로 설정한다. 이후 선형적으로 윈도우 사이즈를 증가시킨다. 리눅스에서는 Fast Retransmit이 아닌 RTO 기반으로 패킷 유실을 확인해도 Fast Recovery를 진행한다.
cong_control
윈도우 사이즈는 아래와 같이 모든 ACK 수신 시 진행하며, 혼란제어 알고리즘에 따라 윈도우 사이즈를 업데이트한다.
1
2
3
4
5
6
7
8
9
/* This routine deals with incoming acks, but not outgoing ones. */
static int tcp_ack(struct sock *sk, const struct sk_buff *skb, int flag)
{
..
tcp_cong_control(sk, ack, delivered, flag, sack_state.rate);
tcp_xmit_recovery(sk, rexmit);
return 1;
...
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
static void tcp_cong_control(struct sock *sk, u32 ack, u32 acked_sacked,
int flag, const struct rate_sample *rs)
{
const struct inet_connection_sock *icsk = inet_csk(sk);
if (icsk->icsk_ca_ops->cong_control) {
icsk->icsk_ca_ops->cong_control(sk, ack, flag, rs);
return;
}
if (tcp_in_cwnd_reduction(sk)) {
// 상태가 안좋으면 윈도우 사이즈 감소
tcp_cwnd_reduction(sk, acked_sacked, rs->losses, flag);
} else if (tcp_may_raise_cwnd(sk, flag)) {
// 상태가 괜찮으면 윈도우 사이즈 증가
tcp_cong_avoid(sk, ack, acked_sacked);
}
tcp_update_pacing_rate(sk);
}
패킷 손실이 발생한 경우
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
/* Enter Loss state. */
void tcp_enter_loss(struct sock *sk)
{
tcp_timeout_mark_lost(sk);
/* Reduce ssthresh if it has not yet been made inside this window. */
// 아래는 임계치를 수정하는 경우이다.
if (icsk->icsk_ca_state <= TCP_CA_Disorder ||
!after(tp->high_seq, tp->snd_una) ||
(icsk->icsk_ca_state == TCP_CA_Loss && !icsk->icsk_retransmits)) {
// 과거 임계치를 저장하고, 임계치 업데이트
tp->prior_ssthresh = tcp_current_ssthresh(sk);
tp->prior_cwnd = tcp_snd_cwnd(tp);
tp->snd_ssthresh = icsk->icsk_ca_ops->ssthresh(sk);
tcp_ca_event(sk, CA_EVENT_LOSS);
tcp_init_undo(tp);
}
// 송신 윈도우 사이즈를 전송 중인 패킷 수 + 1로 조정한다.
tcp_snd_cwnd_set(tp, tcp_packets_in_flight(tp) + 1);
tp->snd_cwnd_cnt = 0;
tp->snd_cwnd_stamp = tcp_jiffies32;
...
}
마치며
실제 구현이 궁금해 리눅스 커널 코드를 들여다봤는데 TFO, TCP-AO 인증, SYN Flooding, PAWS 등 네트워크 관련 이론을 추가로 배울 수 있어 좋았다. 실무에서는 TFO와 같이 최대한 TCP의 성능을 높이려는 노력이 보여 재밌었다. TFO는 소스를 찾아보면 구글에서 제안하고 채택된 기술로 보이는데, QUIC 프로토콜에 이어 역시 구글은 성능 개선에 진심이구나 싶다. 다음에는 Socket 부분을 살펴볼 예정이다.